
操作系统实验
哈工大操作系统实验
- 预备知识:
Boches是一个x86模拟器, 在上面可以运行各种操作系统, 类似于VMvare,但是其比VMware更方便调试。
GCC是编译器, 可以编译C,C++等
GDB是调试器, 与GCC协同作用。
安装实验环境, 参考哈工大李治军操作系统课程实验环境搭建
如果安装时出现Certificate verification failed: The certificate is NOT trusted报错,可能的方法是将https换为http
ubuntu-ports focal 证书过期 · Issue #1342 · tuna/issues · GitHub
Ubuntu和Linux 0.11之间的文件交换
oslab下的hdc-0.11-new.img是0.11内核启动后的根文件系统镜像文件,相当于在bochs虚拟机里装载的硬盘。在Ubuntu上访问其内容的方法是:
1 | sudo ./mount-hdc |
之后,hdc目录下就是和0.11内核一模一样的文件系统了,可以读写任何文件(可能有些文件要用sudo才能访问)。读写完毕,不要忘了卸载这个文件系统:
1 | sudo umount hdc |
注意1:不要在0.11内核运行的时候mount镜像文件,否则可能会损坏文件系统。同理,也不要在已经mount的时候运行0.11内核。
注意2:在关闭Bochs之前,需要先在0.11的命令行运行“sync”,确保所有缓存数据都存盘后,再关闭Bochs。
实验一:操作系统的引导
程序要运行起来,必须要经过四个步骤:预处理、编译、汇编和链接。接下来通过几个简单的例子来详细讲解一下这些过程。

如有一个程序hello.c,通过gcc hello.c生成默认的a.out,然后./a.out即可输出程序执行的结果。
hexdump -C bootsect 将bootsect输出标准的十六进制和ASCII码
编译和链接汇编文件:
1 | as86 -0 -a -o bootsect.o bootsect.s |
1 | dd bs=1 if=bootsect of=Image skip=32 |
以文件bootsect为输入,以每次1byte的速度读写到文件image, 并跳过开头的32byte才开始写入
得到Image后, 将其复制到linux-0.11目录下, 然后再通过./run运行即可, 这样就能在bochs中看到自己想要的信息。
这里的Image联想到, 在VMware中装虚拟机也是通过下载需要的操作系统的镜像, 然后再运行Image镜像即可。
操作系统的引导 | HIT-OSLAB-MANUAL (gitbooks.io)
实验二:系统调用
系统调用 — 哈工大李治军操作系统实验2_weixin_30563917的博客-CSDN博客
操作系统实现系统调用的基本过程是:
1.应用程序调用库函数(API);
2.API将系统调用号存入EAX,把函数参数存入其它通用寄存器,然后通过(int 0x80)中断调用使系统进入内核态;
3.内核中的中断处理函数根据系统调用号,调用对应的内核函数(系统调用),通过宏来调用;
4.系统调用完成相应功能,将返回值存入EAX,返回到中断处理函数;
5.中断处理函数返回到API中;
6.API将EAX返回给应用程序。

main将eax寄存器置72(系统调用编号),触发int 0x80中断 (实际是在库函数中做的)
int 0x80指令查IDT表(中断向量表,由内核初始化)发现DPL=3 ,而CPL = 3(用户态)可以执行
于是将这个IDT表项的段选择子CS 给CS寄存器(例如段选择子为8H=1000,后两位为CPL,特权级别CPL置0),入口函数偏移给IP寄存器
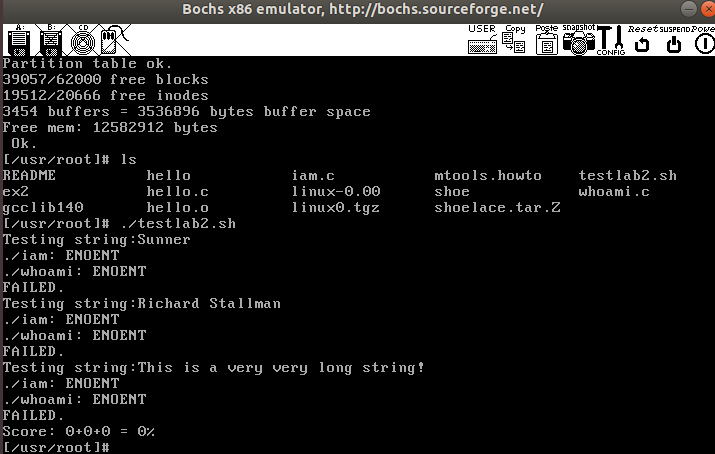
然后执行中断服务程序,中断服务程序调用sys_whoami
sys_whoami里此时可以访问内核态数据(访问100地址的数据)
实验结果:
实验三:进程运行轨迹的跟踪与统计
实验目的
- 掌握Linux下的多进程编程技术;
- 通过对进程运行轨迹的跟踪来形象化进程的概念;
- 在进程运行轨迹跟踪的基础上进行相应的数据统计,从而能对进程调度算法进行实际的量化评价,更进一步加深对调度和调度算法的理解,获得能在实际操作系统上对调度算法进行实验数据对比的直接经验。
实验内容
进程从创建(Linux下调用fork())到结束的整个过程就是进程的生命期,进程在其生命期中的运行轨迹实际上就表现为进程状态的多次切换,如进程创建以后会成为就绪态;当该进程被调度以后会切换到运行态;在运行的过程中如果启动了一个文件读写操作,操作系统会将该进程切换到阻塞态(等待态)从而让出CPU;当文件读写完毕以后,操作系统会在将其切换成就绪态,等待进程调度算法来调度该进程执行……
本次实验包括如下内容:
- 基于模板“process.c”编写多进程的样本程序,实现如下功能:
所有子进程都并行运行,每个子进程的实际运行时间一般不超过30秒;
父进程向标准输出打印所有子进程的id,并在所有子进程都退出后才退出;
在Linux 0.11上实现进程运行轨迹的跟踪。基本任务是在内核中维护一个日志文件/var/process.log,把从操作系统启动到系统关机过程中所有进程的运行轨迹都记录在这一log文件中。
在修改过的0.11上运行样本程序,通过分析log文件,统计该程序建立的所有进程的等待时间、完成时间(周转时间)和运行时间,然后计算平均等待时间,平均完成时间和吞吐量。可以自己编写统计程序,也可以使用python脚本程序—— stat_log.py ——进行统计。
修改0.11进程调度的时间片,然后再运行同样的样本程序,统计同样的时间数据,和原有的情况对比,体会不同时间片带来的差异。
实验总结:
单进程编程所写的程序是顺序执行的,彼此之间有严格的执行逻辑;在没有其他程序的干扰下,数据是同步的,而多进程编程所写的程序是同时执行的,虽然共享文件等,但是由于多个进程之间执行顺序无法得知,故而要考虑进程之间的关系和影响,尤其是数据异步,程序员要做好进程之间同步,通信,互斥等。相比较而言,多进程编程比单进程编程复杂得多,但是用途广泛得多。
为了每个进程可以尽量公平的执行,引入了时间片的概念,即进程允许进行的时间。当到达时间片后,CPU去执行其他进程。
- 时间片变小,进程因时间片到时产生的进程调度次数变多,该进程等待时间越长。
- 然而随着时间片增大,进程因中断或者睡眠进入的进程调度次数也增多,等待时间随之变长。故而需要设置合理的时间片,既不能过大,也不能过小。
实验4 信号量的实现和应用
本次实验的基本内容是:
- 在 Ubuntu 下编写程序,用信号量解决生产者——消费者问题;
- 在 0.11 中实现信号量,用生产者—消费者程序检验之。
在 Ubuntu 上编写应用程序“pc.c”,解决经典的生产者—消费者问题,完成下面的功能:
- 建立一个生产者进程,N 个消费者进程(N>1);
- 用文件建立一个共享缓冲区;
- 生产者进程依次向缓冲区写入整数 0,1,2,…,M,M>=500;
- 消费者进程从缓冲区读数,每次读一个,并将读出的数字从缓冲区删除,然后将本进程 ID 和 + 数字输出到标准输出;
- 缓冲区同时最多只能保存 10 个数。
首先pc.c中用到了sem_open()、sem_close()、sem_wait() 和 sem_post() 等信号量相关的系统调用
1 | sem_t *sem_open(const char *name, unsigned int value); |
sem_open()的功能是创建一个信号量,或打开一个已经存在的信号量。sem_t是信号量类型,根据实现的需要自定义。name是信号量的名字。不同的进程可以通过提供同样的 name 而共享同一个信号量。如果该信号量不存在,就创建新的名为 name 的信号量;如果存在,就打开已经存在的名为 name 的信号量。value是信号量的初值,仅当新建信号量时,此参数才有效,其余情况下它被忽略。当成功时,返回值是该信号量的唯一标识(比如,在内核的地址、ID 等),由另两个系统调用使用。如失败,返回值是 NULL。
sem_wait()就是信号量的 P 原子操作。如果继续运行的条件不满足,则令调用进程等待在信号量 sem 上。返回 0 表示成功,返回 -1 表示失败。(P是消费原子资源)sem_post()就是信号量的 V 原子操作。如果有等待 sem 的进程,它会唤醒其中的一个。返回 0 表示成功,返回 -1 表示失败。(V是产生原子资源)
在操作系统中,P操作和V操作各自的动作是如何定义的?_百度知道 (baidu.com)
sem_unlink的功能是删除名为 name 的信号量。返回 0 表示成功,返回 -1 表示失败。
实现就是首先增加了几个系统调用,需要修改sys.h, system_call.s和unistd.h,然后通过pc.c调用这几个接口。