
MySQL必知必会
第一章:了解MySQL
一些基本概念:
数据库:保存有组织的数据的容器(通常是一个文件或一组文件)。
表:表是一种结构化的文件,可用来存储某种特定类型的数据。表可以保存顾客清单、产品目录,或者其他信息清单。(虽然在相同数据库中不能两次使用相同的表名,但在不同的数据库中却可以使用相同的表)
模式:模式(schema) 关于数据库和表的布局及特性的信息。
列:列(column) 表中的一个字段。所有表都是由一个或多个列组成的。
数据类型:数据类型(datatype) 所容许的数据的类型。每个表列都有相应的数据类型,它限制(或容许)该列中存储的数据。
行:表中的数据是按行存储的,所保存的每个记录存储在自己的行内。一行也叫一个数据库记录。
主键:主键(primary key)一列(或一组列),其值能够唯一区分表中每个行。
SQL语言:SQL(发音为字母S-Q-L或sequel)是结构化查询语言(Structured Query Language)的缩写。SQL是一种专门用来与数据库通信的语言。
DBMS(数据库管理系统)。数据库软件应称未DBMS,即数据库管理系统;MySQL是一种DBMS,即它是一种数据库软件。
第二章:MySQL简介
MySQL开源, 免费,易用。
DBMS可分为两类:一类为基于共享文件系统的DBMS,另一类为基于客户机—服务器的DBMS。
客户机软件都要与服务器软件进行通信。
MySQL的使用可以用命令行, IDE等等。
一些MySQL工具:MySQL命令行实用程序,MySQL Administrator,MySQL Query Browser
MySQL Administrator(MySQL管理器)是一个图形交互客户机,用来简化MySQL服务器的管理。
MySQL Query Browser为一个图形交互客户机,用来编写和执行MySQL命令。
感觉还是Navicat Premium好用, 但是需要付费。
第三章:使用MySQL
一些基本的命令及作用:
1 | show databases; #显示数据库 |
- 什么是自动增量?
在每个行添加到表中时,MySQL可以自动地为每个行分配下一个可用编号,不用在添加一行时手动分配唯一值。
第四章:检索数据
一些小tips:
- 如果没有明确排序查询结果(下一章介绍),则返回的数据的顺序没有特殊意义。
- 多条SQL语句必须以分号(;)分隔。
- SQL语句不区分大小写。
- 在处理SQL语句时,其中所有空格都被忽略。
- 在选择多个列时,一定要在列名之间加上逗号,但最后一个列名后不加。
1 | select id,user from tp_one; #从tp_one表中选取id,user列 |
第五章:排序探索数据
1 | select id from tp_one order by math;#默认按照math升序的顺序输出id, 升序为asc |
第六章:数据过滤
where语句可以进行数据过滤,在同时使用ORDER BY和WHERE子句时,应该让ORDER BY位于WHERE之后
where操作符:
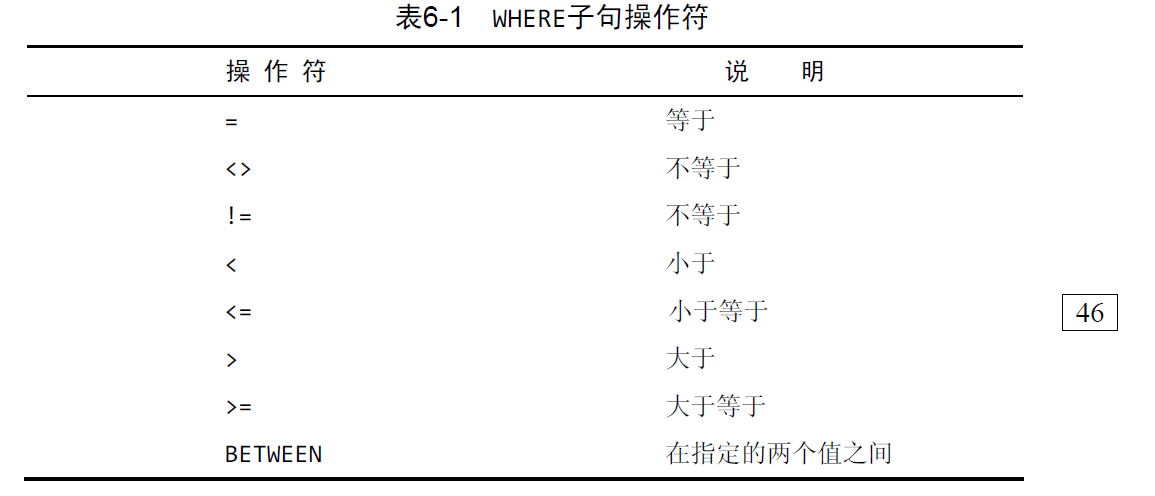
- where语句的用法
1 | select prod_name, prod_price from products where prod_price = 2.5;#条件过滤, 选取价格为2.5的产品名字和价格 |
第七章:数据过滤
1 | select prod_id from products WHERE vend_id = 1003 and prod_price <= 10;#与逻辑关系 |
第八章:用通配符进行过滤
1 | select prod_id, prod_name from products where prod_name like 'jet%'; # 找到以jet起头的单词 |
通配符处理速度很慢,因此不是万不得已不要轻易用通配符;此外应该注意通配符的位置。
第九章:用正则表达式进行搜索
1 | select prod_name from products where prod_name REGEXP '1000' order by prod_name;# 1000作为正则表达式处理,只要列值中有1000,就输出这个列值 |




第十章:创建计算字段
1 | select CONCAT(vend_name,'(',vend_country,')') from vendors order by vend_name; #CONCAT关键字将字段之间连接起来 |
注意,多数DBMS用+或者||进行拼接,MySQL用concat进行拼接。
第十一章:使用数据处理函数
- 文本处理函数
MySQL支持使用函数来处理数据,但是函数具有可移植性不如直接使用SQL语句的特点。
1 | SELECT vend_name, upper(vend_name) as vend_name_upcase FROM vendors order by vend_name; |


Soundex返回与串读音近似的元素。
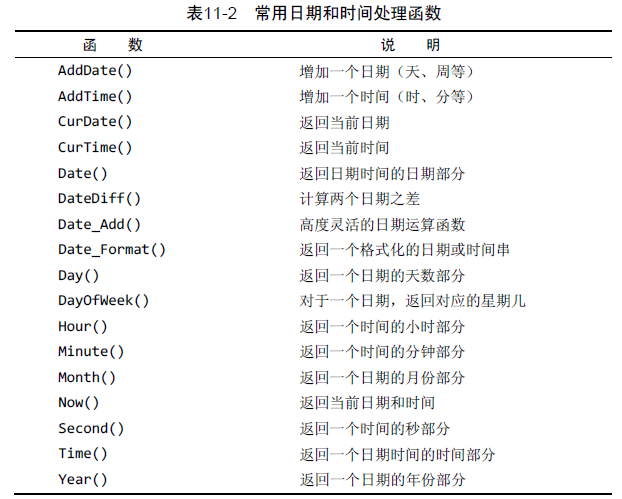
- 日期和时间处理函数
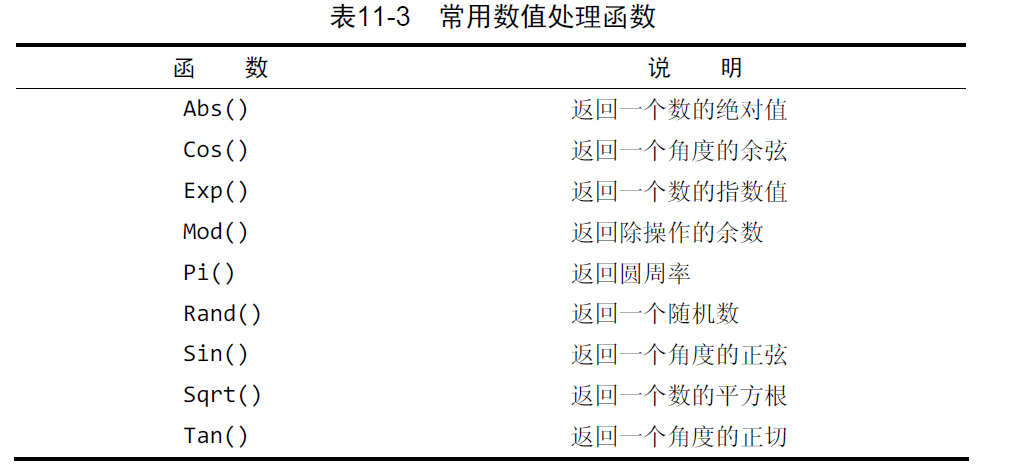
- 数值处理函数
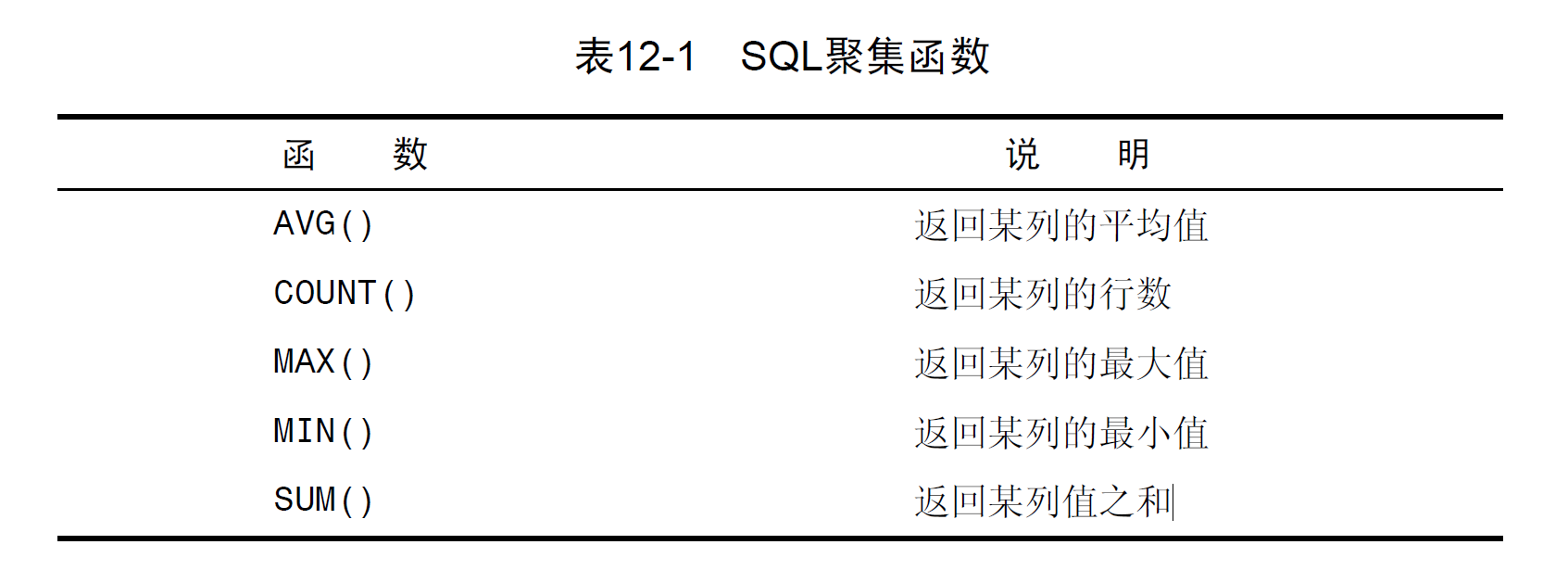
第十二章:汇总数据
1 | SELECT AVG(prod_price) as avg_price from products where vend_id = 1003; #avg_price是一个别名 |
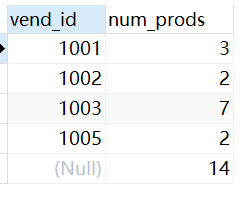
第十三章:分组数据
1 | select count(*) as num_prods from products where vend_id = 1003;#查询products中vend_id是1003的数量记作num_prods |
在具体使用GROUP BY子句前,需要知道一些重要的规定。
- GROUP BY子句可以包含任意数目的列。
- 在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)。
GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用表达式,则必须在GROUP BY子句中指定相同的表达式。不能使用别名。 - 除聚集计算语句外,SELECT语句中的每个列都必须在GROUP BY子句中给出。如果分组列中具有NULL值,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。
- GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
目前为止所学过的所有类型的WHERE子句都可以用HAVING来替代。唯一的差别是
WHERE过滤行,而HAVING过滤分组。
分组(GROUP BY)和排序(ORDER BY)的联系和区别:


第十四章:使用子查询
SELECT语句是SQL的查询。迄今为止我们所看到的所有SELECT语句都是简单查询,即从单个数据库表中检索数据的单条语句。但是一些复杂的逻辑一个select可能不能提取出想要的信息,这时就要使用子查询。
1 | SELECT cust_name, cust_contact FROM customers WHERE cust_id IN (SELECT cust_id FROM orders WHERE order_num IN (SELECT order_num FROM orderitems where prod_id = 'TNT2')); #后面select作为前面select的条件 |
第十五章:联结表
SQL最强大的功能之一就是能在数据检索查询的执行中联结(join)表。联结是利用SQL的SELECT能执行的最重要的操作,很好地理解联结及其语法是学习SQL的一个极为重要的组成部分。
外键(foreign key) 外键为某个表中的一列,它包含另一个表的主键值,定义了两个表之间的关系。
笛卡儿积(cartesian product) 由没有联结条件的表关系返回的结果为笛卡儿积。检索出的行的数目将是第一个表中的行数乘以第二个表中的行数。
1 | SELECT vend_name, prod_name, prod_price FROM vendors, products WHERE vendors.vend_id = products.vend_id ORDER BY vend_name, prod_name; #创建联结 |
目前为止所用的联结称为等值联结(equijoin),它基于两个表之间的相等测试。这种联结也称为内部联结。其实,对于这种联结可以使用稍微不同的语法来明确指定联结的类型。下面的SELECT语句返回与前面例子完全相同的数据:
第十六章:创建高级联结
1 | select CONCAT(vend_name,'(',vend_country,')') from vendors order by vend_name; #CONCAT关键字将字段之间连接起来 |
第十七章:组合查询
多数SQL查询都只包含从一个或多个表中返回数据的单条SELECT语句。MySQL也允许执行多个查询(多条SELECT语句),并将结果作为单个查询结果集返回。这些组合查询通常称为并(union)或复合查询(compound query)。
UNION实际上可以将两个select的结果联合起来
1 | SELECT vend_id, prod_id, prod_price FROM products WHERE prod_price <= 5 UNION SELECT vend_id, prod_id, prod_price FROM products WHERE vend_id IN (1001,1002); #union联合时不包含重复的行 |
第十八章:全文本搜索
MySQL支持几种基本的数据库引擎。并非所有的引擎都支持本书所描述的全文本搜索。两个最常使用的引擎为MyISAM和InnoDB,前者支持全文本搜索,而后者不支持。这就是为什么虽然本书中创建的多数样例表使用InnoDB , 而有一个样例表(productnotes表)却使用MyISAM的原因。如果你的应用中需要全文本搜索功能,应该记住这一点。
在索引之后,SELECT可与Match()和Against()一起使用以实际执行搜索。
假如创建表时有一个列名为note_text的列,为了进行全文本搜索,MySQL根据子句FULLTEXT(note_text)的指示对它进行索引。这里的FULLTEXT索引单个列,如果需要也可以指定多个列。
在索引之后,使用两个函数Match()和Against()执行全文本搜索,其中Match()指定被搜索的列,Against()指定要使用的搜索表达式。包含词越靠前,优先级越高。
1 | SELECT note_text FROM productnotes WHERE MATCH(note_text) AGAINST('rabbit'); #Match()指定被搜索的列,Against()指定要使用的搜索表达式。 |


第十九章:插入数据
顾名思义,INSERT是用来插入(或添加)行到数据库表的。插入可以用几种方式使用:
1 | INSERT INTO customers VALUES(NULL, 'Pep', 'main street', 'LA', 'CA', '90046', 'USA', NULL, NULL); #第一个NULL实际上mysql自动对cust_id加1 |
第二十章:更新和删除数据
SET命令用来将新值赋给被更新的列。如这里所示,SET子句设置cust_email列为指定的值:
如果用UPDATE语句更新多行,并且在更新这些行中的一行或多行时出一个现错误,则整个UPDATE操作被取消(错误发生前更新的所有行被恢复到它们原来的值)。为即使是发
生错误,也继续进行更新,可使用IGNORE关键字。
1 | UPDATE customers SET cust_email = 'elmer@fudd.com' WHERE cust_id = 10005; #更新数据 |
如果省略了WHERE子句,则UPDATE或DELETE将被应用到表中所有的行。
MySQL没有撤销(undo)按钮。应该非常小心地使用UPDATE和DELETE,否则你会发现自己更新或删除了错误的数据。
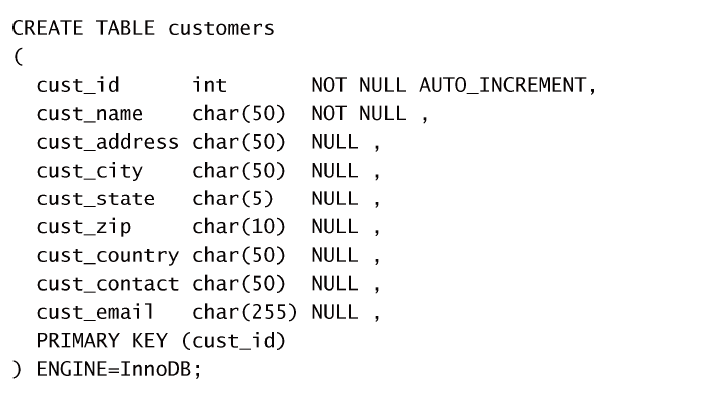
第二十一章:创建和操纵表
为利用CREATE TABLE创建表,必须给出下列信息:
- 新表的名字,在关键字CREATE TABLE之后给出;
- 表列的名字和定义,用逗号分隔。
在创建新表时,指定的表名必须不存在,否则将出错。如果要防止意外覆盖已有的表,SQL要求首先手工删除该表(请参阅后面的小节),然后再重建它,而不是简单地用创建表语句覆盖它。如果你仅想在一个表不存在时创建它,应该在表名后给出IF NOT EXISTS。
正如所述,主键值必须唯一。即,表中的每个行必须具有唯一的主键值。如果主键使用单个列,则它的值必须唯一。如果使用多个列,则这些列的组合值必须唯一。主键为其值唯一标识表中每个行的列。主键中只能使用不允许NULL值的列。允许NULL值的列不能作为唯一标识。
这就是AUTO_INCREMENT发挥作用的时候了。AUTO_INCREMENT告诉MySQL,本列每当增加一行时自动增量。每个表只允许一个AUTO_INCREMENT列,而且它必须被索引(如,通过使它成为主键)。
AUTO_INCREMENT自动生成的值可以覆盖,也可以通过last_insert_id()函数获得这个值。SELECT last_insert_id()实际上就是返回最后一个AUTO_INCREMENT值。
创建表时还可以通过default关键词给定默认值。与大多数DBMS不一样,MySQL不允许使用函数作为默认值,它只支持常量。
MySQL有一个具体管理和处理数据的内部引擎。在你使用CREATE TABLE语句时,该引擎具体创建表,而在你使用SELECT语句或进行其他数据库处理时,该引擎在内部处理你的请求。
以下是几个需要知道的引擎:
- InnoDB是一个可靠的事务处理引擎(参见第26章),它不支持全文本搜索;
- MEMORY在功能等同于MyISAM,但由于数据存储在内存(不是磁盘)中,速度很快(特别适合于临时表);
- MyISAM是一个性能极高的引擎,它支持全文本搜索(参见第18章),但不支持事务处理。
此外,可以通过ALTER TABLE更新表
1 | ALTER TABLE vendors ADD vend_phone CHAR(20); #表中插入一个列 |
ALTER TABLE的一种常见用途是定义外键。下面是用来定义本书中的表所用的外键的代码:

删除表:DROP TABLE customers2
重命名表:RENAME TABLE customers2 TO customers
总结:本章介绍了几条新SQL语句。CREATE TABLE用来创建新表,ALTERTABLE用来更改表列(或其他诸如约束或索引等对象),而DROP TABLE用来完整地删除一个表。这些语句必须小心使用,并且应在做了备份后使用。本章还介绍了数据库引擎、定义主键和外键,以及其他重要的表和列选项。
第二十二章:使用视图
视图是虚拟的表。与包含数据的表不一样,视图只包含使用时动态检索数据的查询。
我们已经看到了视图应用的一个例子。下面是视图的一些常见应用。
- 重用SQL语句。
- 简化复杂的SQL操作。在编写查询后,可以方便地重用它而不必知道它的基本查询细节
- 使用表的组成部分而不是整个表。
- 保护数据。可以给用户授予表的特定部分的访问权限而不是整个表的访问权限。
- 更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。
下面是关于视图创建和使用的一些最常见的规则和限制。
- 与表一样,视图必须唯一命名(不能给视图取与别的视图或表相同的名字)。
- 对于可以创建的视图数目没有限制。
- 为了创建视图,必须具有足够的访问权限。这些限制通常由数据库管理人员授予。
- 视图可以嵌套,即可以利用从其他视图中检索数据的查询来构造一个视图。
- ORDER BY可以用在视图中,但如果从该视图检索数据SELECT中也含有ORDER BY,那么该视图中的ORDER BY将被覆盖。
- 视图不能索引,也不能有关联的触发器或默认值。
- 视图可以和表一起使用。例如,编写一条联结表和视图的SELECT语句。
如何使用视图:
- 视图用CREATE VIEW语句来创建。
- 使用SHOW CREATE VIEW viewname;来查看创建视图的语句。
- 用DROP删除视图,其语法为DROP VIEW viewname;。
- 更新视图时,可以先用DROP再用CREATE,也可以直接用CREATE OR REPLACE VIEW。如果要更新的视图不存在,则第2条更新语句会创建一个视图;如果要更新的视图存在,则第2条更新语句会替换原有视图。
1 | CREATE VIEW productcustomers AS SELECT cust_name, cust_contact, prod_id FROM customers, orders, orderitems WHERE customers.cust_id = orders.cust_id AND orderitems.order_num = orders.order_num;#创建视图 |
可以看出,视图极大地简化了复杂SQL语句的使用。利用视图,可一次性编写基础的SQL,然后根据需要多次使用。
基本上可以说,如果MySQL不能正确地确定被更新的基数据,则不允许更新(包括插入和删除)。这实际上意味着,如果视图定义中有以下操作,则不能进行视图的更新:
- 分组(使用GROUP BY和HAVING);联结;子查询;并;聚集函数(Min()、Count()、Sum()等);DISTINCT;导出(计算)列。
第23章:使用存储过程
经常会有一个完整的操作需要多条语句才能完成。可以创建存储过程。存储过程简单来说,就是为以后的使用而保存的一条或多条MySQL语句的集合。可将其视为批文件,虽然它们的作用不仅限于批处理。
换句话说,使用存储过程有3个主要的好处,即简单、安全、高性能。
1 | CREATE PROCEDURE productpricing( ) |
带输入输出参数:
1 | CREATE PROCEDURE ordertotal( |
智能存储过程:
1 | -- Name: ordertotal |
检查存储过程:
1 | SHOW CREATE PROCEDURE ordertotal; |
第24章:使用游标
游标(cursor)是一个存储在MySQL服务器上的数据库查询,它不是一条SELECT语句,而是被该语句检索出来的结果集。在存储了游标之后,应用程序可以根据需要滚动或浏览其中的数据。
1 | CREATE PROCEDURE processorders() BEGIN DECLARE ordernumbers CURSOR FOR SELECT order_num FROM orders; END; #创建游标 |
循环检索数据:
1 | drop PROCEDURE processorders; |
1 | DROP PROCEDURE processorders; |
第25章:使用触发器
在创建触发器时,需要给出4条信息:
- 唯一的触发器名;
- 触发器关联的表;
- 触发器应该响应的活动(DELETE、INSERT或UPDATE);
- 触发器何时执行(处理之前或之后)。
1 | CREATE TRIGGER neworder AFTER INSERT ON orders FOR EACH ROW SELECT NEW.order_num INTO @onum; #创建insert触发器 |
CREATE TRIGGER用来创建名为newproduct的新触发器。触发器可在一个操作前(BEFORE)或后(AFTER)执行,这里给出了AFTER INSERT,所以此触发器将在INSERT语句成功后执行。此触发器还指定FOR EACH ROW,因此代码对每个插入行执行。
第26章 管理事务处理
并非所有引擎都支持明确的事务处理管理。MyISAM和InnoDB是两种最常使用的引擎。前者不支持明确的事务处理管理,而后者支持。
事务处理(transaction processing)可以用来维护数据库的完整性,它保证成批的MySQL操作要么完全执行,要么完全不执行。
在使用事务和事务处理时,有几个关键词汇反复出现。下面是关于事务处理需要知道的几个术语:
- 事务(transaction)指一组SQL语句;
- 回退(rollback)指撤销指定SQL语句的过程;
- 提交(commit)指将未存储的SQL语句结果写入数据库表;
- 保留点(savepoint)指事务处理中设置的临时占位符(placeholder),你可以对它发布回退(与回退整个事务处理不同)。
1.开始事务
1 | START TRANSACTION |
2.回滚ROLLBACK
1 | SELECT * FROM ordertotals; |
事务处理用来管理INSERT、UPDATE和DELETE语句。你不能回退SELECT语句。(这样做也没有什么意义。)你不能回退CREATE或DROP操作。事务处理块中可以使用这两条语句,但如果你执行回退,它们不会被撤销。
3.提交commit
一般的MySQL语句都是直接针对数据库表执行和编写的。这就是所谓的隐含提交(implicit commit),即提交(写或保存)操作是自动进行的。但是,在事务处理块中,提交不会隐含地进行。为进行明确的提交,使用CoMMIT语句,如下所示:
1 | START TRANSACTION; |
4.保留点SAVEPOINT
简单的ROLLBACK和COMMIT语句就可以写入或撤销整个事务处理。但是,只是对简单的事务处理才能这样做,更复杂的事务处理可能需要部分提交或回退。
为了支持回退部分事务处理,必须能在事务处理块中合适的位置放置占位符。这样,如果需要回退,可以回退到某个舌位符。这些占位符称为保留点。为了创建占位符,可如下使用SAVEPOINT.
1 | SAVEPOINT delete1;#每个保留点都取标识它的唯一名字,以便在回退时,MySQL知道要回退到何处。 |
保留点在事务处理完成后自动释放,5.x之后也可以用RELEASE SAVEPOINT 明确的释放保留点!在mysql代码中可以设置任意多的保留点,越多越好,保留点越多,就能按照自己意愿灵活的进行回退。
5.自动提交autocommit
1 | SET autocommit=0; |
第27章 全球化和本地化
数据库表被用来存储和检索数据。不同的语言和字符集需要以不同的方式存储和检索。
在讨论多种语言和字符集时,将会遇到以下重要术语:
- 字符集为字母和符号的集合;
- 编码为某个字符集成员的内部表示;
- 校对为规定字符如何比较的指令。
使用字符集和校对顺序
- 查看支持的字符集列表:
show character set; - 查看支持校对的字符集列表:
show collation; - 查看系统或数据库的字符集和校对:
show variables like 'character%'; show variables like 'collation%'; - 为某个表或某个列指定字符集和校对,不指定使用数据库默认
1 | create table xxx |
第28章:安全管理
28.1 访问控制
MySQL服务器的安全基础是: 用户应该对他们需要的数据具有适当的访问权,既不能多也不能少。换句话说,用户不能对过多的数据具有过多的访问权。
28.2 管理用户
需要获得所有用户账号列表时。为此,可使用以下代码:
1 | mysql> USE mysql; |
- 分析:mysql数据库有一个名为user的表, 它包含所有用户账号。 user表有一个名为user的列,它存储用户登录名。新安装的服务器可能只有一个用户(如这里所示), 过去建立的服务器可能具有很多用户。
28.2.1 创建用户账号
为了创建一个新用户账号,使用CREATE USER语句,如下所示:
1 | CREATE user ben IDENTIFIED BY 'p@$$wOrd'; |
- 分析:CREATE USER创建一个新用户账号。在创建用户账号时不一定需要口令,不过这个例子用IDENTIFIED BY ‘p@$$wOrd’给出了一个口令。
为重新命名一个用户账号,使用RENAME USER语句,如下所示:
1 | RENAME USER ben TO bforta; |
28.2.2 删除用户账号
为了删除一个用户账号(以及相关的权限),使用DROP USER语句,如下所示:
1 | DROP USER bforta; |
28.2.3 设置访问权限
在创建用户账号后,必须接着分配访问权限。新创建的用户账号没有访问权限。它们能登录MySQL,但不能看到数据,不能执行任何数据库操作。为看到赋予用户账号的权限,使用SHOW GRANTS FOR,如下所示:
- 分析:输出结果显示用户bforta有一个权限USAGE ON .。 USAGE表示根本没有权限(我知道,这不很直观),所以,此结果表示在任意数据库和任意表上对任何东西没有权限。
为设置权限,使用GRANT语句。 GRANT要求你至少给出以下信息:
- 要授予的权限;
- 被授予访问权限的数据库或表;
- 用户名。
以下例子给出GRANT的用法:
1 | GRANT SELECT ON crashcourse.* TO bforta; |
- 分析:此GRANT允许用户在crashcourse.*( crashcourse数据库的所有表)上使用SELECT。 通过只授予SELECT访问权限,用户bforta对crashcourse数据库中的所有数据具有只读访问权限。
SHOW GRANTS反映这个更改:
- 分析:每个GRANT添加(或更新)用户的一个权限。 MySQL读取所有
授权,并根据它们确定权限。
GRANT的反操作为REVOKE,用它来撤销特定的权限。下面举一个例子:
1 | REVOKE SELECT ON crashcourse.* FROM bforta; |
- 分析:这条REVOKE语句取消刚赋予用户bforta的SELECT访问权限。 被撤销的访问权限必须存在,否则会出错。
GRANT和REVOKE可在几个层次上控制访问权限:
- 整个服务器,使用GRANT ALL和REVOKE ALL;
- 整个数据库,使用ON database.*;
- 特定的表,使用ON database.table;
- 特定的列;
- 特定的存储过程。
表28-1列出可以授予或撤销的每个权限。
| 权 限 | 说 明 |
|---|---|
| ALL | 除GRANT OPTION外的所有权限 |
| ALTER | 使用ALTER TABLE |
| ALTER ROUTINE | 使用ALTER PROCEDURE和DROP PROCEDURE |
| CREATE | 使用CREATE TABLE |
| CREATE ROUTINE | 使用CREATE PROCEDURE |
| CREATE TEMPORARY TABLES | 使用CREATE TEMPORARY TABLE |
| CREATE USER | 使用CREATE USER、 DROP USER、 RENAME USER和REVOKE ALL PRIVILEGES |
| CREATE VIEW | 使用CREATE VIEW |
| DELETE | 使用DELETE |
| DROP | 使用DROP TABLE |
| EXECUTE | 使用CALL和存储过程 |
| FILE | 使用SELECT INTO OUTFILE和LOAD DATA INFILE |
| GRANT OPTION | 使用GRANT和REVOKE |
| INDEX | 使用CREATE INDEX和DROP INDEX |
| INSERT | 使用INSERT |
| LOCK TABLES | 使用LOCK TABLES |
| PROCESS | 使用SHOW FULL PROCESSLIST |
| RELOAD | 使用FLUSH |
| REPLICATION CLIENT | 服务器位置的访问 |
| REPLICATION SLAVE | 由复制从属使用 |
| SELECT | 使用SELECT |
| SHOW DATABASES | 使用SHOW DATABASES |
| SHOW VIEW | 使用SHOW CREATE VIEW |
| SHUTDOWN | 使用mysqladmin shutdown(用来关闭MySQL) |
| SUPER | 使用CHANGE MASTER、 KILL、 LOGS、 PURGE、 MASTER 和SET GLOBAL。还允许mysqladmin调试登录 |
| UPDATE | 使用UPDATE |
| USAGE | 无访问权限 |
28.2.4 更改口令
为了更改用户口令,可使用SET PASSWORD语句。新口令必须如下加密:


第29章:数据库维护检查表键
检查表键
1 | analyze table orders; |
检查表键是否存在错误
1 | # 检查表是否存在错误 |
check table用来针对许多问题对表进行检查。(在MyISAM上还对索引进行检查)
1 | check table orders,orderitems changed; #检查自最后一次检查以来改动过的表 |
mysqld命令行选项:
- —help显示帮助——一个选项列表;
- —safe-mode装载减去某些最佳配置的服务器;
- —verbose显示全文本消息(为获得更详细的帮助消息与—help
联合使用); - —version显示版本信息然后退出。
查看日志文件:
1) 错误日志。它包含启动和关闭问题以及任意关键错误的细节。此日志通常名为hostname.err,位于data目录中。此日志名可以用—log-error命令行选项更改。
2) 查询日志。它记录所有的MySQL活动,在诊断问题时非常有用。此日志文件可能会很快地变得非常大,因此不应该长期使用它。此日志通常名为hostname.log,位于data目录中。此名字可以用—log命令行选项更改。
3) 二进制日志。它记录更新过数据(或者可能更新过数据)的所有语句。此日志通常名为hostname-bin,位于data目录内。此名字可以用—log-bin命令行选项更改。注意,这个日志文件是MySQL5中添加的,以前的MySQL版本中使用的是更新日志。
4) 缓慢查询日志。此日志记录执行缓慢的任何查询。这个日志在确定数据库何处需要优化很有用。此日志同城名为hostname-slow.log,位于data目录中。此名字可以用—log-slow-queries命令行选项更改。
使用日志时,可用flush logs语句来刷新和重新开始所有日志文件。
第30章:改善性能
1 | SHOW VARIABLES; #查看当前的状态 |