
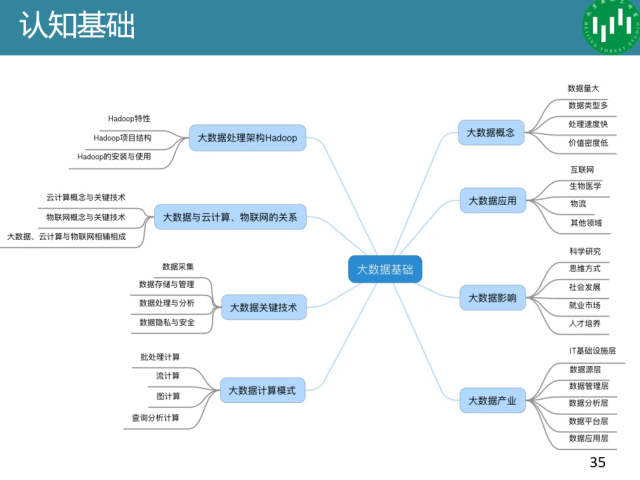
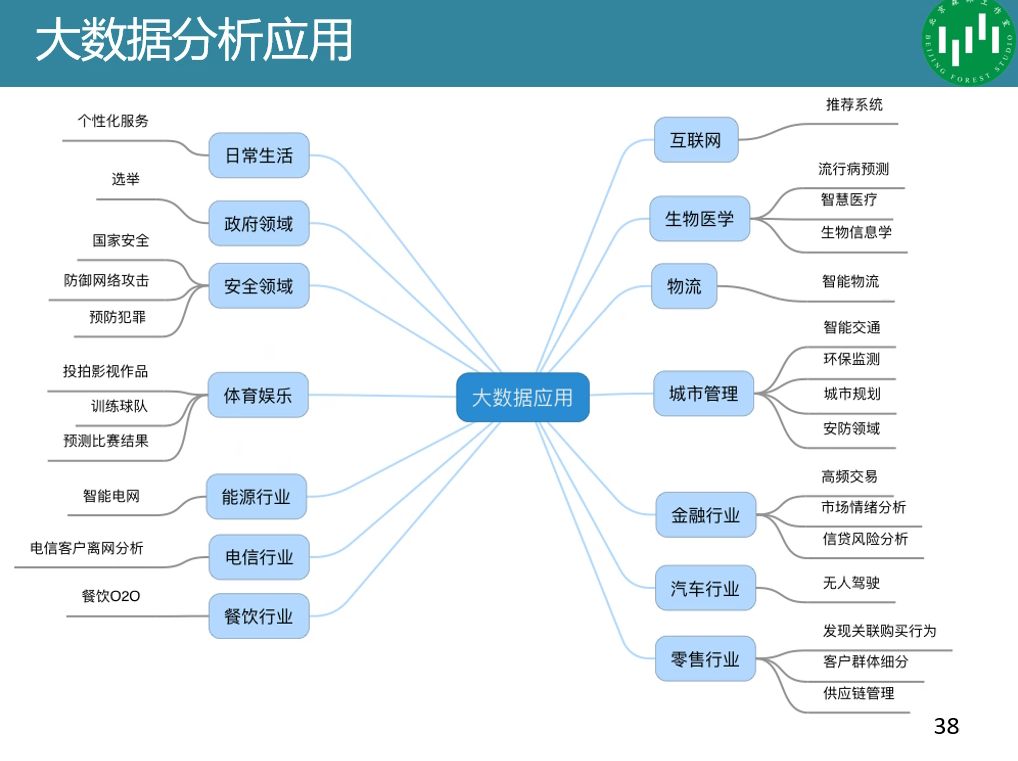
大数据
大数据的大小在不同领域有不同的定义,一般认为TB及或者PB集就属于大数据,但是要是全国人体的健康指标可能几万条数据就够了。
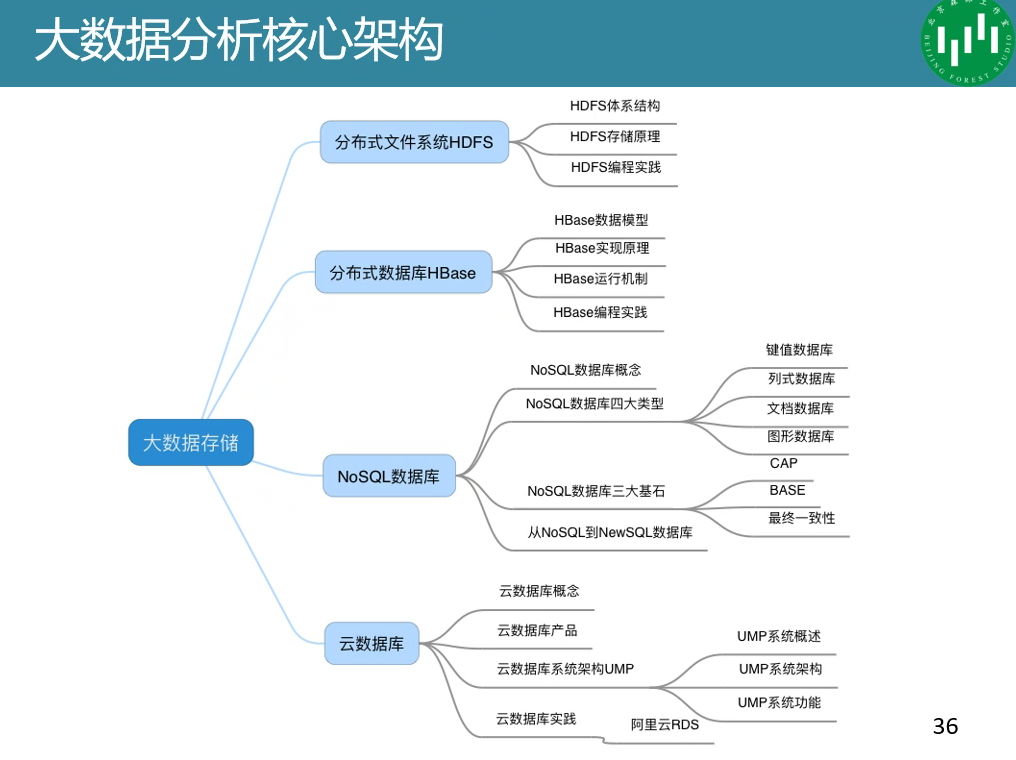
开源分布式计算平台,核心组件包括HDFS,MapReduce等
CPU:强控制弱计算
GPU:强计算弱控制
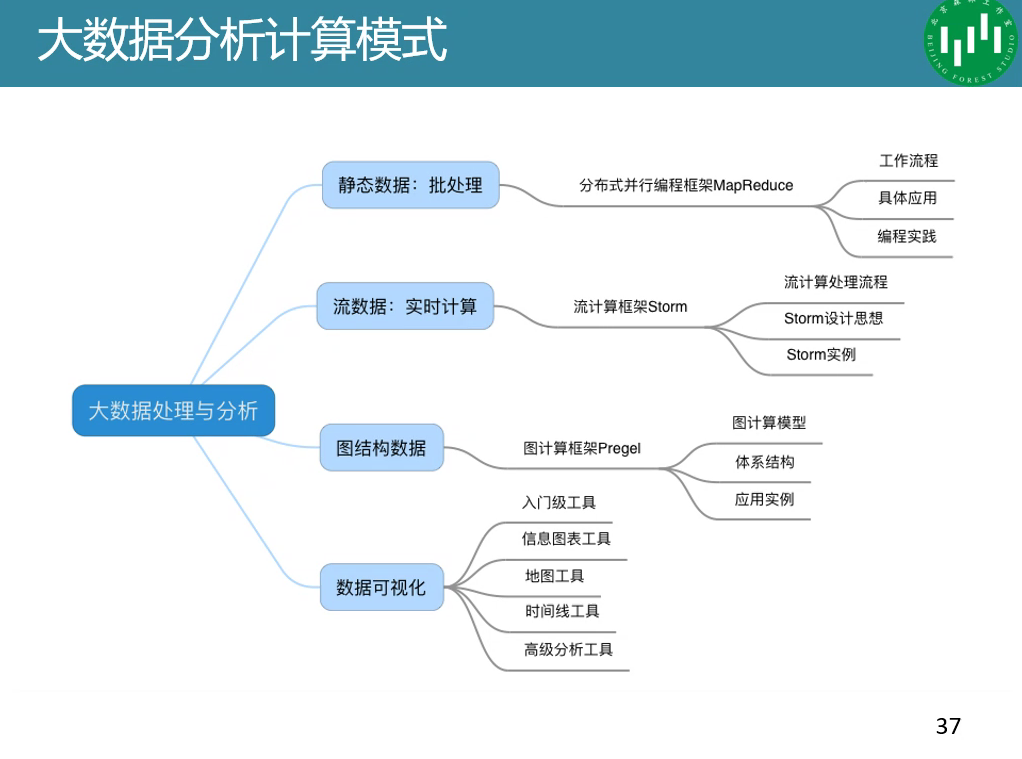
Spark:内存型计算
Hadoop:稳定,将中间结果存在硬盘上
Mapreduce:谷歌提出的并行计算模型,当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。Map面对的是杂乱无章的互不相关的数据,它解析每个数据,从中提取出key和value,也就是提取了数据的特征。经过MapReduce的Shuffle阶段之后,在Reduce阶段看到的都是已经归纳好的数据了,在此基础上我们可以做进一步的处理以便得到结果。
流计算Storm:快速的批处理,Storm用来实时处理数据,特点:低延迟、高可用、分布式、可扩展、\数据不丢失**。提供简单容易理解的接口,便于开发。