
手写数字识别
手写数字识别(CS229 ex3)
首先确定这个问题是一个分类问题。
- 数据(data)的结构:
X的维度是5000*400,其中5000是数字的总个数,400是数据的像素点是20*20的;y的维度是5000*1, 存的是数据对应的真实值;sample_idx是从data中选取了100个数字,sample_images是这100个数字的像素值;
sigmoid函数:可以将一个实数映射为一个(0,1)区间内的数;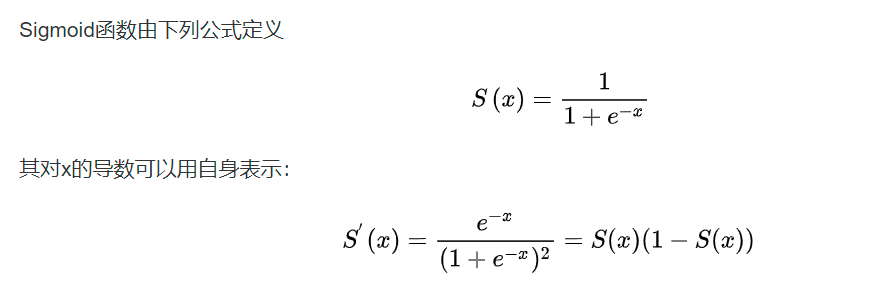
优点:平滑、易于求导。
缺点:激活函数计算量大,反向传播求误差梯度时,求导涉及除法;反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。
1 | #定义sigmoid函数 |
希望代价函数是一个凸函数,而不是具有多个局部最优解。

根据此思想,可以定义代价函数如下:
1 | def costReg(theta, X, y, lamda): |
正则化方法:L1和L2 regularization、数据集扩增、dropout - bonelee - 博客园 (cnblogs.com)
reg表示正则化,在代价函数的后面加一个常数项,减小每个数据的权重,防止过拟合,注意正则化不包括theta0
梯度下降算法_梯度下降算法中的偏导公式推导_weixin_39882948的博客-CSDN博客
梯度函数的计算本质上就是对代价函数求偏导
1 | def gradientReg_noLoop(theta, X, y, lamda): |
然后就是对数据进行分类,分类函数为:
1 | # 分类函数 |
特别注意:区分矩阵点乘 @ 和矩阵乘法 * ,写错的话可能会导致难以 debug 的错误!!!
最后是对数据进行测试:
1 | # 测试函数 |
主函数部分:
1 | data = loadData('ex3data1.mat') |
学习率为 0 时训练结果:accuracy = 97.26%
学习率为 0.5 时训练结果:accuracy = 95.1%
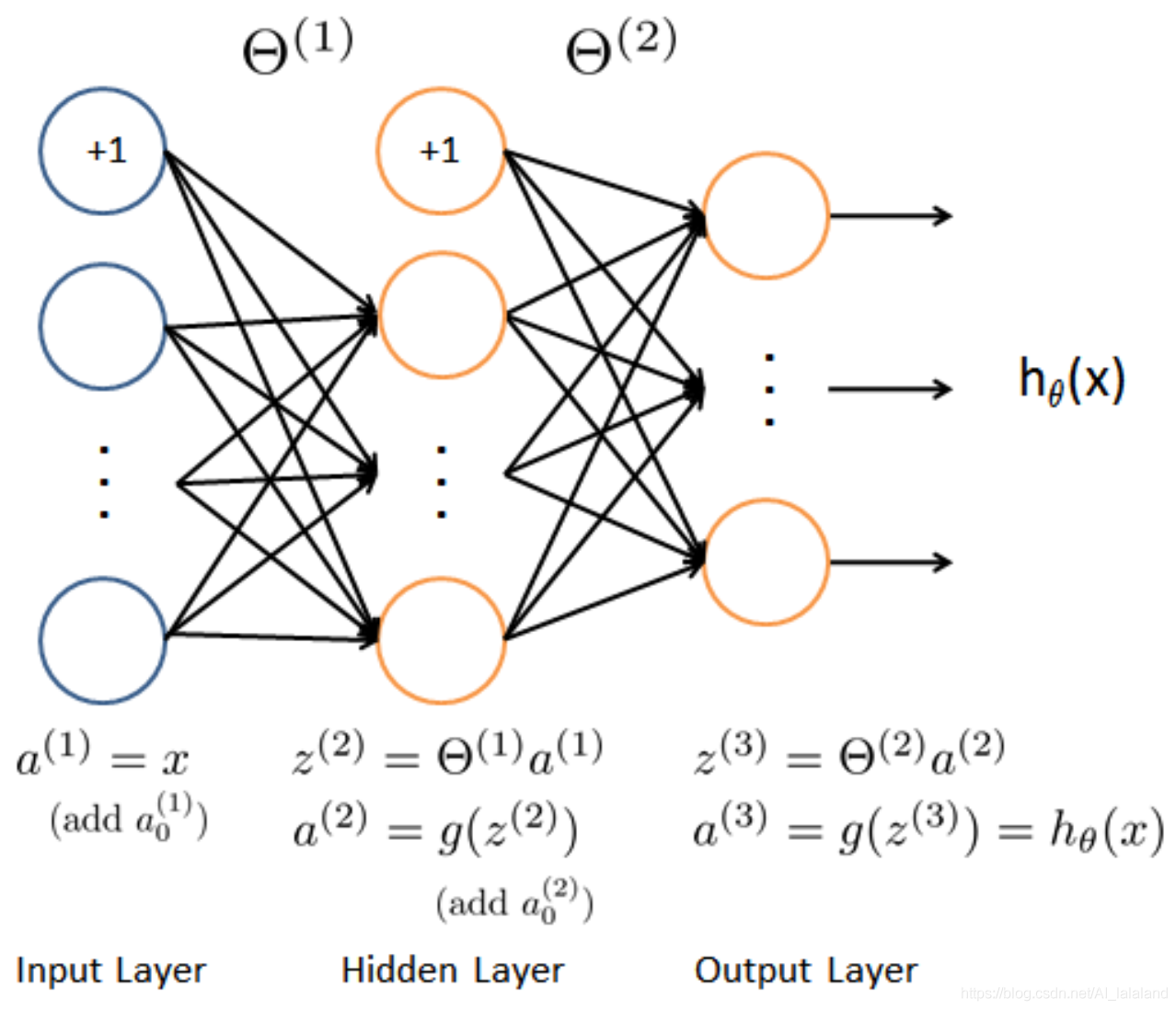
卷积神经网络:已经给了训练的theta,包括theta1和theta2;
根据神经网络的结构(一层输入层 400+1 ,一层隐藏层 25+1 ,一层输出层 10),计算结果:
theta1的维度是(25, 401),theta2的维度是(10, 26)
前向传播算法:
1 | # -*- coding: utf-8 -*- |
神经网络和反向传播算法:

首先要明白一点,BP 做的事情是求代价函数 J 对参数 theta (也可以用 weight 表示)的偏导数,根据链式法则,表示如下:
吴恩达机器学习CS229A_EX4_神经网络与反向传播算法_Python3_AI_lalaland的博客-CSDN博客
1 | # -*- coding: utf-8 -*- |
最终达到了accuracy = 99.16%