操作系统 - 内存管理和调度
L20 内存使用和分段
计算机执行程序的本质就是取指—>执行。
内存的使用:将程序放在内存中,PC指向开始地址。
call 40可以理解为将IP指针赋给40。也就是从物理地址40开始执行。但是这样有一个缺点,就是main()函数必须放在物理地址为40的位置。
实际上应该使用重定位,也就是将物理地址40修改为1040作为逻辑地址,实际上就是每个地址加上了个基址,即main()函数相对于整个程序是在40这个位置上。
完成重定位的时间:编译时 载入时 运行时
可以在编译时加入基址实现重定位,但是这样有一个缺点:编译的时候就得知道哪一段内存是空闲的,在实际的系统中很难确定。
可以在载入时实现重定位。但是程序载入后可能还需要移动,如果地址已经确定也不好,这时候就需要用到交换机制。
如果进程1阻塞了,就将其从内存取出,放到磁盘中。然后将进程2的内存地址改变。因此载入后的程序也可能发生移动,这样载入时的地址和真正执行程序时的地址也不一样。
最好的方式:运行时重定位
每执行一条指令时,都要根据逻辑地址算出物理地址,即地址翻译,这种方式无论程序放在内存中的哪一块都可以。程序执行起来时,就将基地址(base地址)放在PCB中。然后开始取址执行,执行程序时把指令放在CPU中,然后再根据程序中的偏移地址做判断。当进程发生切换时,PCB会跟着切换,这时候基地址也会跟着PCB一起切换。
然而实际中的程序并不是整个放在内存的连续地址中的,程序往往分成若干个段,每个段都有各自的用途。比如代码段只读,代码段/数据段不会动态增长。
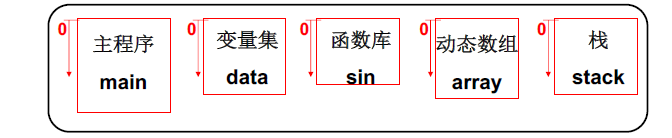
举个例子:主程序和变量集之间就需要分段。主程序一般是只读的,变量集应该是可写的。如果把他们放在一个段,程序就需要写入权限,这样主程序也有可能会被改变。
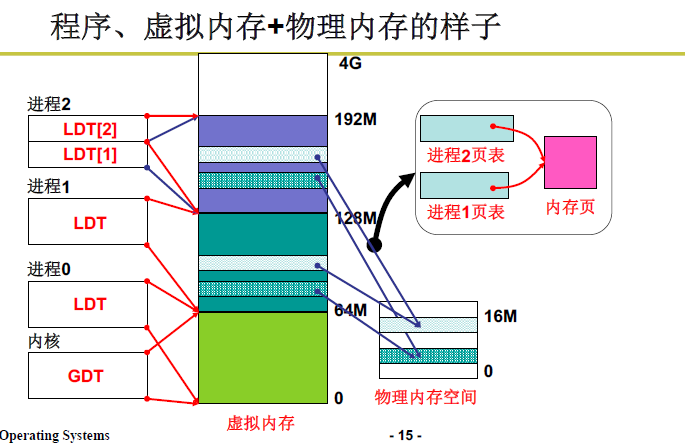
将程序分段,可以让内存管理更高效。将程序中的各个段分别放在内存中。重定位时段的基址实际上就是各自段的基址,即PCB需要放每一个段的基址,也就是进程段表。
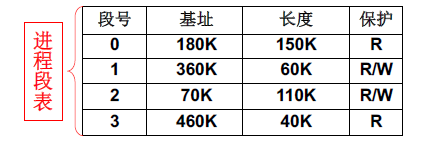
GDT(Global Description Table)表实际上就是通过找操作系统的进程对应的段表就是GDT表。实际上每个进程都有对应的一套段表,也就是LDT(Local Descriptor Table)。进程切换也对应的LDT表的切换,LDT表赋给PCB。
操作系统启动进程0,shell启动进程1.
总结起来就是三个步骤:
- 将代码进行分段,这部分是编译时做的。
- 在内存中找到一块空闲的分区。
- 用LDT表,PCB等将代码在内存中的位置的映射关系记录好。
L21 内存分区与分页
如何在内存中找到一段空闲的区域?内存怎么划分?
用的是可变分区的思想,也就是根据段的大小来为其分配空间。
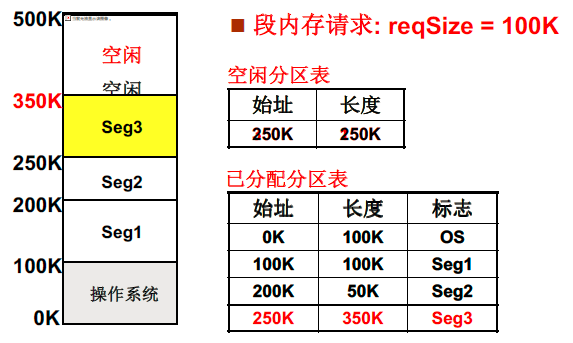
释放完空间如何利用内存分片?
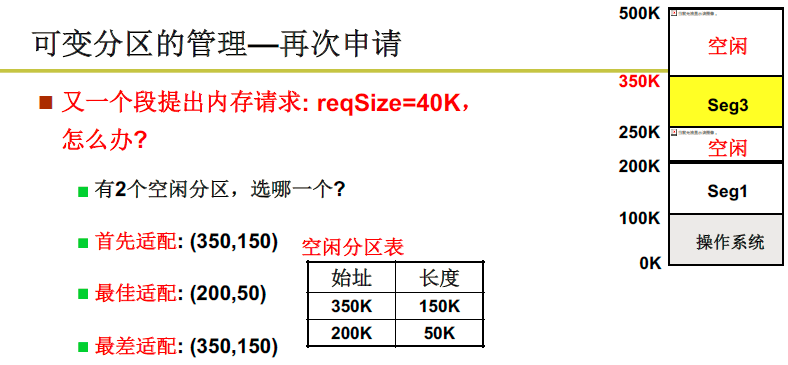
最佳适配分割完后会产生一些小的碎片(复杂度O(n));首先适配申请的速度比较快(复杂度O(1))。
问题:如果某操作系统中的段内存请求很不规则,有时候需要很大的一个内存块,有时候又很小,这时候最佳适配比较合适。
实际内存中采用分页来解决内存分区导致的内存效率问题。虚拟内存采用分区的方法,物理内存采用分页的方法。
可变分区存在的问题就是存在碎片,这就造成可能一个总空闲空间 > 请求空间,但是存不了的情况。这时候就需要内存紧缩。但是内存紧缩存在一个问题就是速度太慢。
内存分页就是将内存分成很多个页,然后针对每个段的内存请求,系统一页一页的向上取整分配给这个段,只有页内碎片,没有其他碎片。

页也对应了一个表,用来记录每页的页号,页框号及其对应的内存地址。分页是由MMU做的,根据每个分页的内存大小通过移位寄存器进行移位。
L22 多级页表与快表
分页的优点就是内存碎片比较小,但是单独的分页存在问题,这个问题需要多级页表和快表来解决。分页机制和多级页表和快表结合起来就形成了一套比较完整的机制。
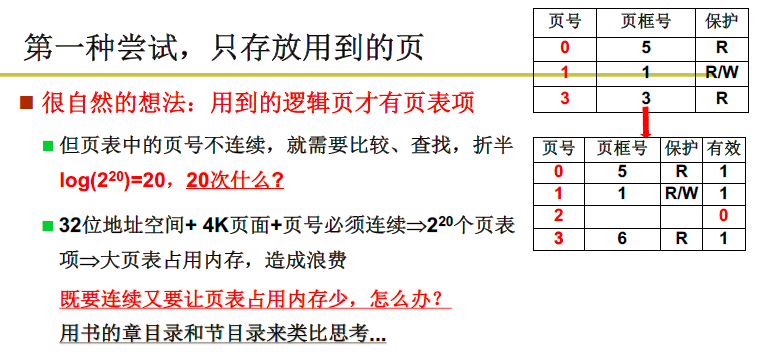
产生问题的原因:为了提高内存空间利用率,页应该减小,但是页减小了页表就大了。页表也需要占据空间。
页面尺寸通常为4K,而地址是32位的,有2^20个页面,2^20个页表项都得放在内存中,需要4M内存;
系统中并发10个进程,就需要40M内存; 而实际中大部分的逻辑地址都不会用到。
一个想法:把不适用的逻辑页号从页表中去掉。但是页表中的页号不连续,就需要比较,查找,折半,这样速度很慢。因为CPU花费时间主要就是在与IO的交互中,计算花费的时间占比很少。
如果页号连续只需要加一个偏移,这样速度就快了,但是如果这样如果页号中间有空位也不能删除了
请教下,操作系统里分页存储的页框和页号有什么区别啊?_百度知道 (baidu.com)
多级页表可以解决这个问题。也就是按照目录的思想,要找的目标在第几章第几节,可以不从前向后找,而是首先找到对应的章再向后找,这样大大提升了效率
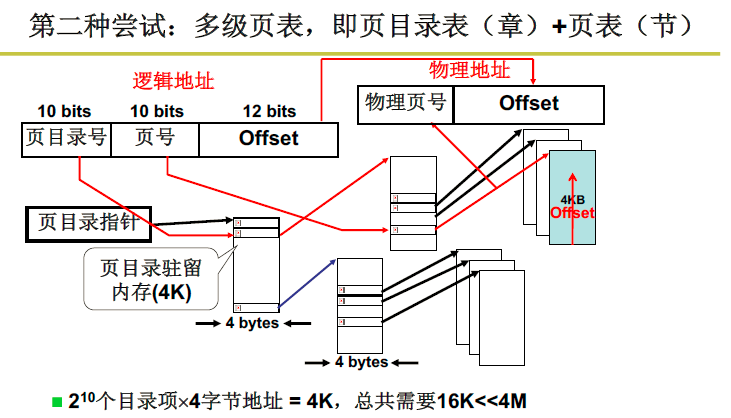
虽然在空间上节约了空间,但是需要找章和节找两次,因此时间花的更多了。如果目录很多,花费的时间就很多,这时候就需要快表。
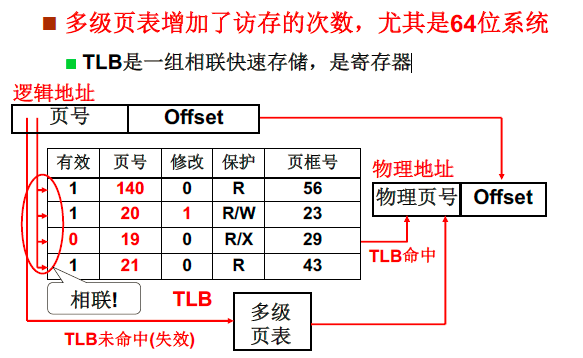
TLB是一组相联快速存储,是寄存器,可以理解为快表可以快速的知道内容在第几章,这样效率就会高。快表只记录一些可能出现概率高的内容。


L23 段页结合的实际内存管理
从应用程序角度出发,首先从虚拟内存中选取段分给程序的每个段作为映射地址,再将虚拟内存中的段分割成固定大小的页,每一页再映射到实际的物理内存上。
段面向用户,页面向硬件。
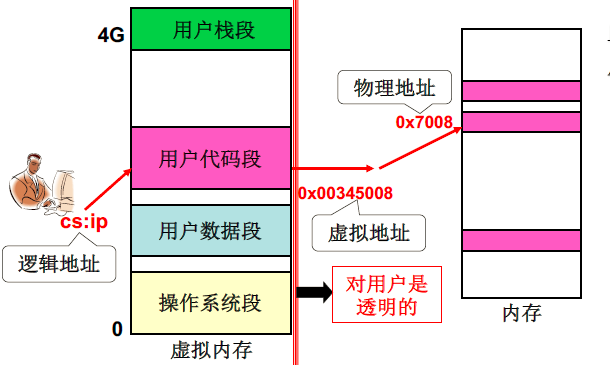
第一次的地址翻译是基于段的地址翻译,第二次地址翻译是基于页的地址翻译;
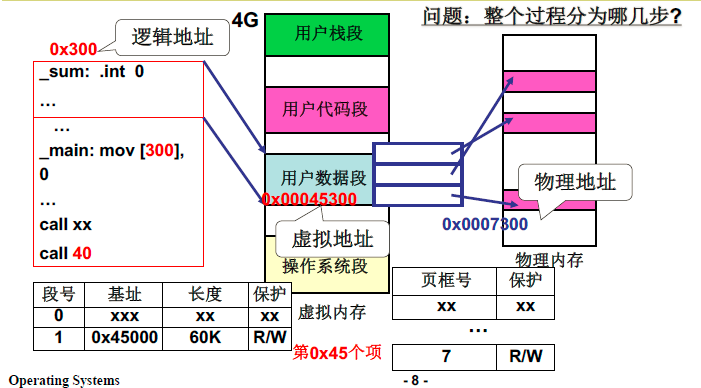
可以总结为五个步骤:
- 在虚拟内存中划分出一段区域
- 将程序对应的各个段放在虚拟内存中(虚拟内存实际上不存在),就是建立段表
- 在物理内存中找到空闲页
- 建立页表,进行磁盘读写,将程序对应的各个段真正放在物理内存中
- 执行程序,能够实现重定位使用内存
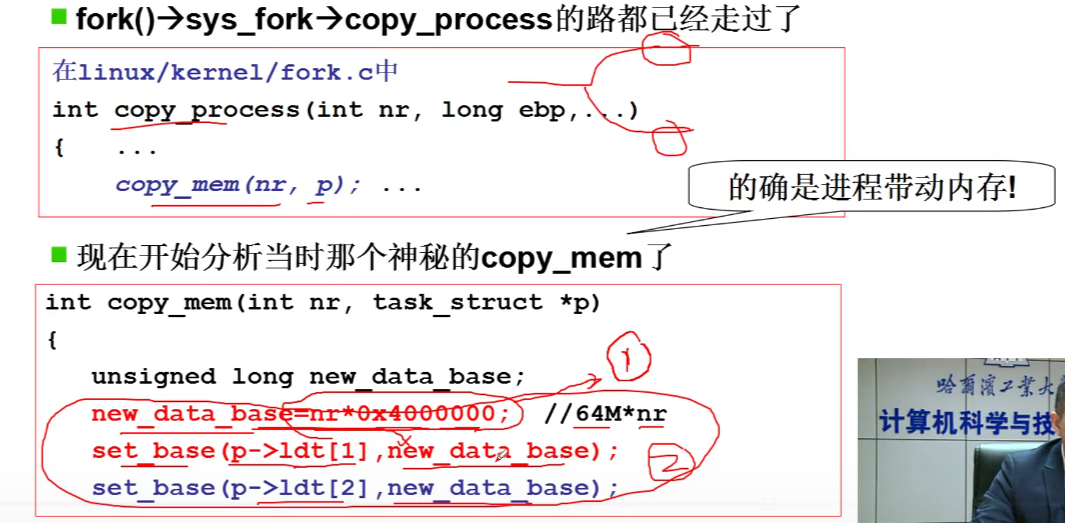
首先创建进程,copy_process为进程划分一段区域,copy_mem中new_data_base对应虚拟内存的分割,不同的进程对应不同的虚拟内存,然后set_base就是建立填写段表,p指的是PCB,会随着进程的切换而切换。
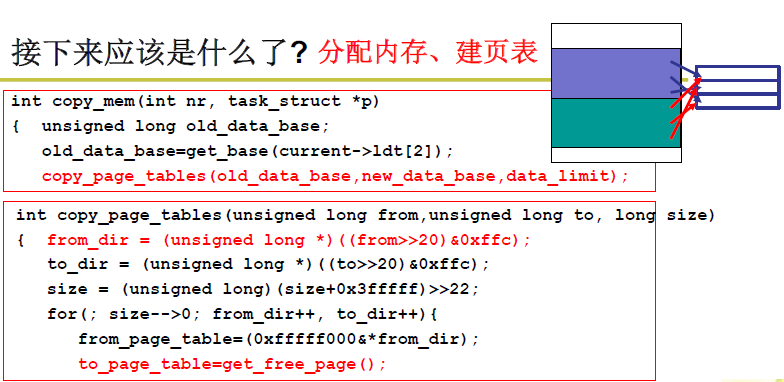

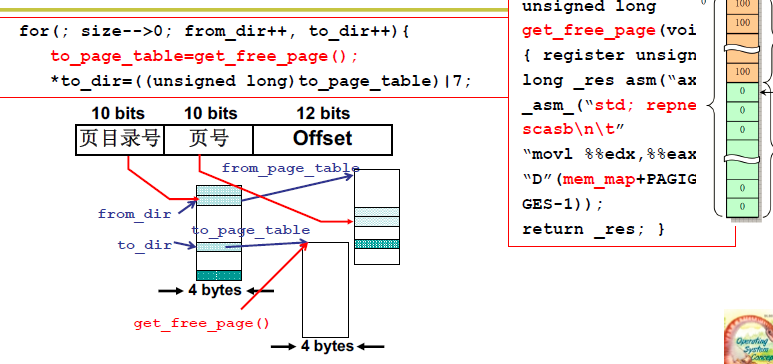
接下来就是分配内存,建立页表。不同的进程之间共享一套页。copy_page_table就是赋值之前的进程的虚拟地址对应的页,将当前进程对应的虚拟地址映射到物理地址上。右移20位是为了找到页目录号。(实际上应该右移22位,但是页目录指针为4byte,因此右移20位),然后异或0xffc 也就是将最后两位置为0。size—是为了处理多个页目录。get_free_table实际上就是进行章的切换,这也是多级页表的优点。
最后一步就是执行程序:
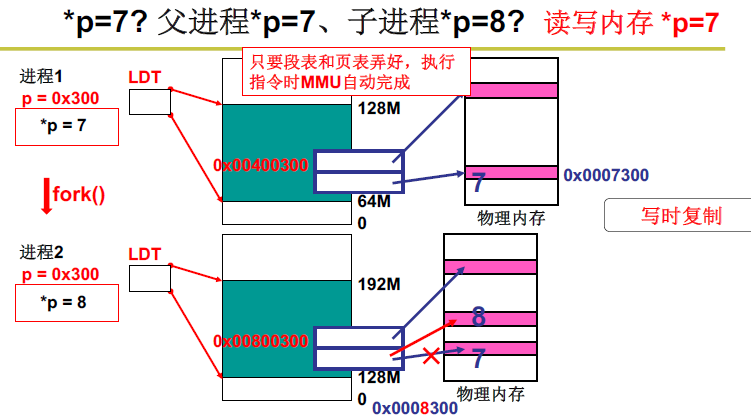
多个进程在内存中的地址相互影响可以消除,并且实现了进程切换时内存也会跟着切换。
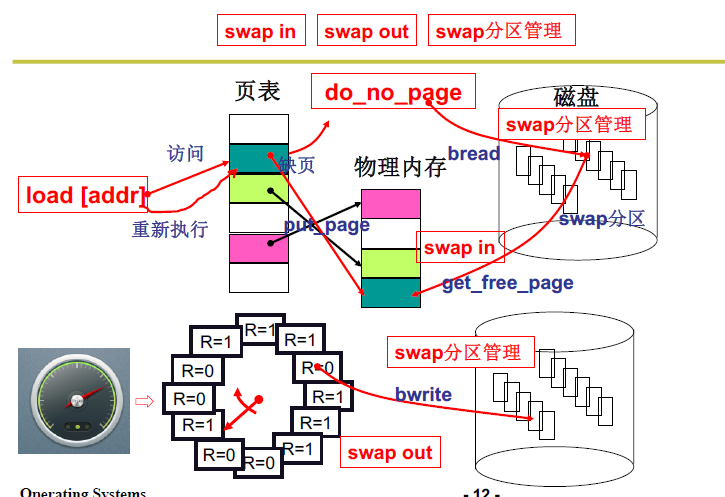
L24 内存换入-请求调页(Swap in)
内存的核心就是通过虚拟内存实现分段和分页,而内存的换入换出是为虚拟内存设计的。
用换入换出可以实现”大内存”,虚拟内存可以类比为仓库,物理地址可以类比为门店。请求就相当于有需求,只有有需求才将虚拟内存映射到物理内存上。
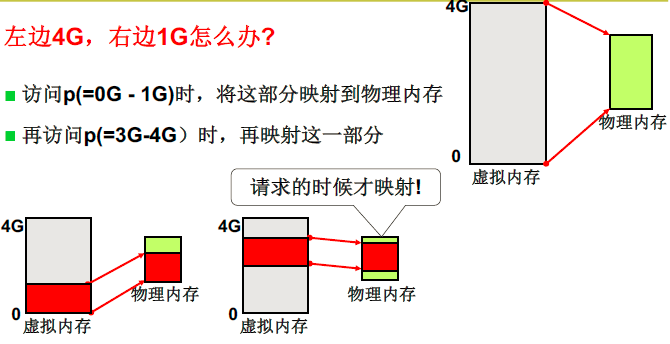
实现换入:请求调页,当发现程序调用内存的部分对应的页表没有在物理内存中,就要MMU启动中断,这时候就需要MMU(memory management unit)内存管理单元请求调页,在页表中找到缺少的页换入到物理内存中。
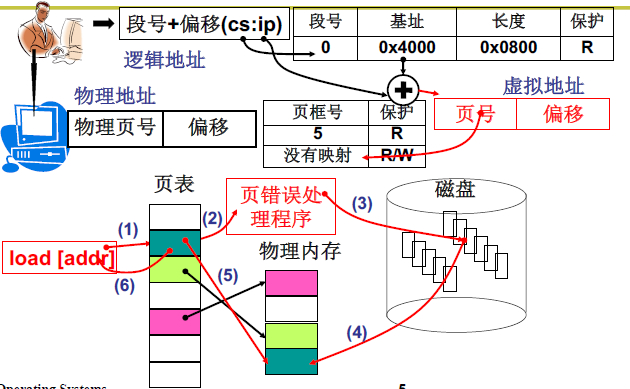
L25 内存换出(swap out)
因为内存的大小是有限的,不能总是换入

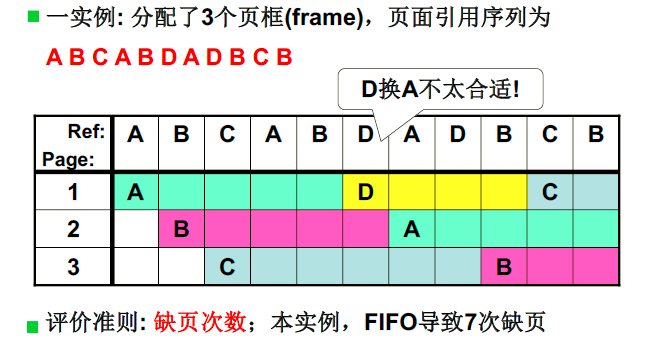
需要选择一页淘汰,换出到磁盘,选择哪一页?
- FIFO,最容易想到,但如果刚换入的页马上又要换出怎么办?
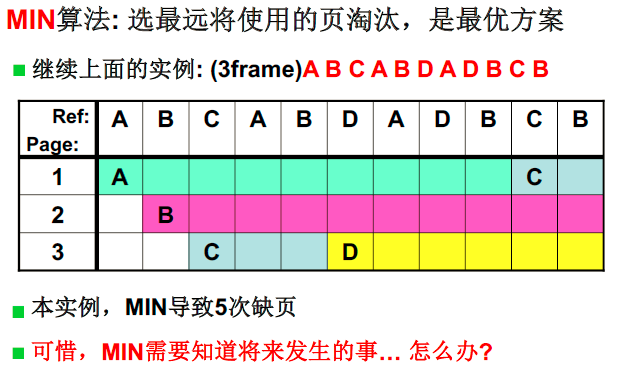
- 有没有最优的淘汰方法? MIN
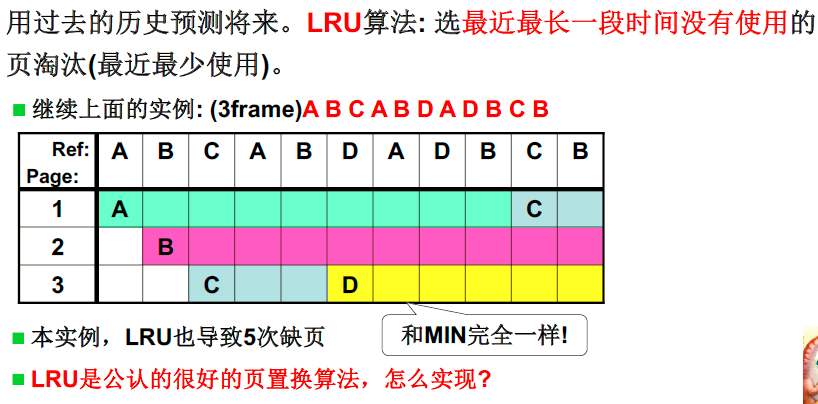
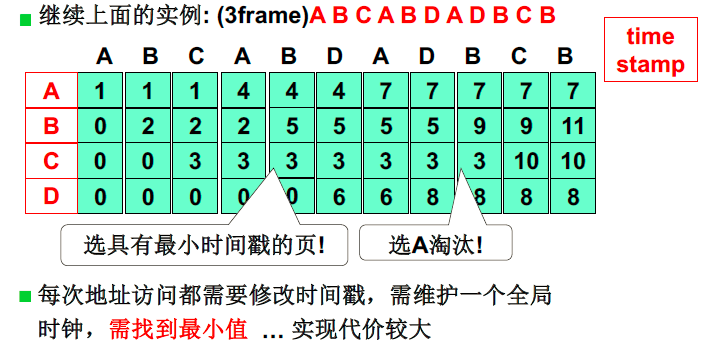
- 最优淘汰方法能不能实现,是否需要近似? LRU
FIFO方法:
已经在内存中不缺页,不在内存中都是缺页。
MIN页面置换:
LRU(least recent used)页面置换:
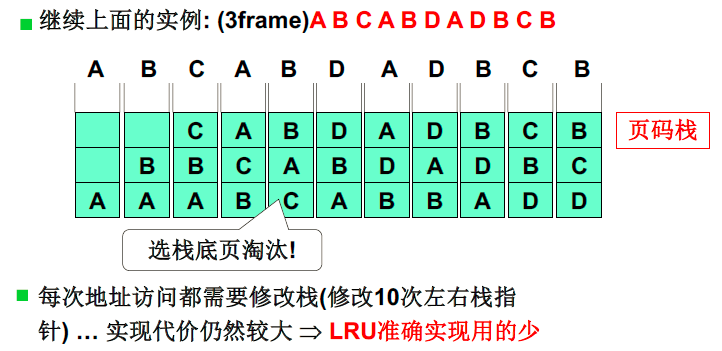
另一种实现方式:页码栈
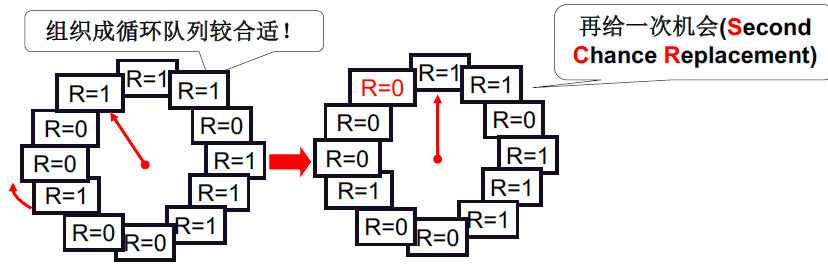
LRU近似实现- 将时间计数变为是和否
每个页加一个引用位(reference bit),每次访问一页时,硬件自动设置该位
选择淘汰页:扫描该位,是1时清0,并继续扫描;是0时淘汰该页
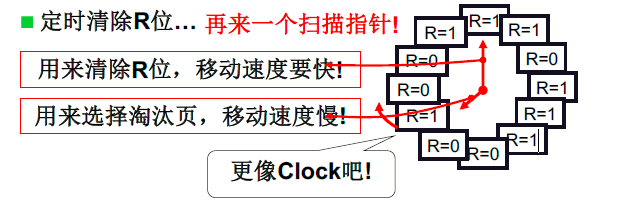
但是如果缺页很多,所有的R全为1,这样就会使得算法近似为FIFO,因此需要定时的将一些位从1变到0.
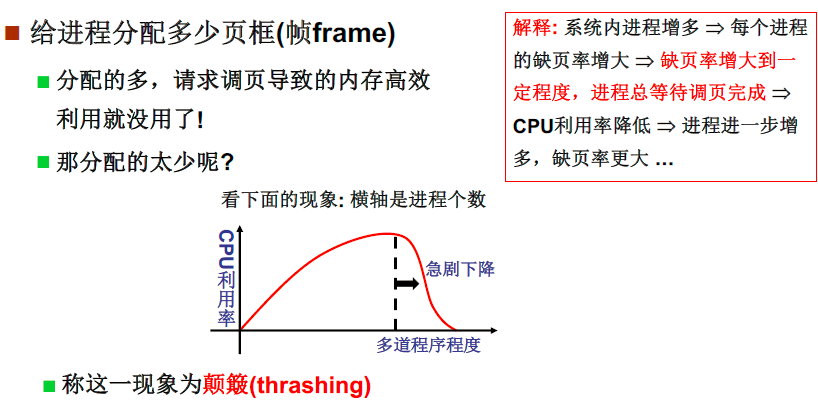
另外一个问题,需要分配给每个进程多少页?
分配的多,请求调页导致的内存高效利用就没用了!
分配的太少,会使得换页次数太多,CPU利用率下降。
换入和换出的结合: