
命名数据网络路由和转发
5.1 路由和转发概述:
NDN采用基于名字进行路由和转发的机制,因为名字空间无限,不涉及地址有限的问题。(存疑,IP虽然地址有限,但是长度一样方便管理,NDN这种方式名字长度不一样对转发是否有影响?)
转发层和路由层相互分离,转发层考虑了具有状态的数据平面的状态信息,使NDN的转发策略有IP没有的自适应性和多路径性。(实际上就是IP网络路由表只能选择一个最优的下一条地址转发,而NDN根据各个接口的优先级排序进行转发);传统IP网络中的路由算法也适用于NDN。
NDN新增加了一个PIT,用于记录转发的请求和指导数据包的传输路径
IP网络路由转发流程:
- 路由器从收到的数据包的首部提取目的IP地址。
- 判断是不是直接在接口完成交付,如果不是,将数据包发送给下一跳路由。
- 如果路由表有默认路由,就发给默认路由。
IP存在的问题是“聪明的路由,笨拙的转发”。路由有状态和自适应性,但是转发有状态和适应性。
NDN网络路由转发机制:
- 发送端发送Interest包。
- 路由器接收到包后,首先判断CS中是否有,如果有直接将Data返回请求的节点。没有就在PIT中找是不是有这个名字包的请求,如果之前就有请求了只要将PIT这个包的条目后面加上请求端进入路由器的节点编号即可。要是没有就把请求信息写入PIT,接着路由器就根据FIB判断Interest包从哪个接口发出。
- 如果转发过程某个节点缓存了与Name匹配的数据时,节点就响应Interest包,返回Data。
- 路由器收到返回的Data包,根据PIT判断从哪个端口返回Data包。
NDN的优势体现在:
- 转发有状态,有灵活的转发策略。
- 如果转发中途节点的CS就有请求信息,就不用到目的节点找了。
- 数据回传不依赖端到端连接,而是依赖PIT中记录的请求包编号。
- Interest包中有随机非重复的标志,即nonce字段,NDN的路由节点可以识别并丢弃返回原请求节点的Interest包,也就是避免了环路路由。
5.2 网络的性能评价指标:
吞吐量:单位时间成功传输的数据包数量,MSPS(Million Search Per Second)
内存效率:进程所占内存与总内存的比值。
更新率:内容发布和删除的更新。
前缀劫持:就是丢包,导致请求方发出的请求超时。
查找延时,可扩展性,连接失败,阻塞等。
5.3 NDN路由策略:
分布式路由策略,每个节点周期性的从相邻节点获得网络状态信息,并将本节点的路由决策告诉周围各个节点。
5.3.1 OSPFN协议
它是OSPF路由协议的一个扩展版本,适用于NDN,并将其部署在NDN的测试床上。OSPFN定义了一种新的不透明的链路状态通告(OLSA),用于在路由消息中携带名称前缀。它为每个名称前缀计算出最佳的下一跳,并插入到FIB表当中,网络管理员可以手动为OSPFN配置一个除了最佳下一跳以外的可选下一跳列表,并插入到FIB表中。
NDN路由器并行的运行CCND,OSPFN,OSPFD(OSPF Daemon)。系统流程为
- OSPFN读取配置文档,为每一个命名前缀建立OLSA,以便其向后向网络广播。
- OSPFN向本地的OSPFD发送命名OLSA,OSPFD将收到的OLSA泛洪到整个网络中。
- 每个节点的OSPFD收到OLSA,将OLSA传递给本地的OSPFN。OSPFN获取OLSA的路由ID号。
- OSPFN判断是不是其他路由器的OLSA,如果是,读取OLSA的命名前缀,创建包含命名前缀和初始路由的表项,为命名前缀创建FIB条目,将它们插入到CCND中。
5.3.2 NLSR协议
NLSR: 命名数据链路状态路由协议_阙建明的博客-CSDN博客_nlsr
作为NDN上第一个分布式的路由协议,NLSR的设计需要回答以下几个在NDN上独有的问题:
- 命名(Naming):如何给路由器(routers)、链接(links)和路由更新(routing updates)命名?
- 信任(Trust):如何分发路由器的加密密钥(cryptographic keys),以及如何获得对这些密钥的信任
- 信息传播(Information Dissemination):如何在网络中传播路由更新?(基于IP的路由协议采用推的方式将路由更新发送给其他路由器,而在NDN网络中则需要路由器主动去拉取所有更新)
- 多路径(Multipath):如何产生并排序下一跳以促进多跳转发?
与IP链路状态路由协议的区别:
- 利用Interest/Data包实现路由更新信息的广播,并对所有的链路状态通告进行签名和验证,使更新信息的真实性得到验证。
- 为每个命名前缀创建了一张转发选项表,包含优先级排序的接口。
NLSR主要解决的问题:命名,安全,路由更新信息的传播,多路径,故障和恢复检测。
1. 命名:
NDN路由器的命名要考虑属于哪一个网络,哪一个站点和路由器的具体名称。
NLSR解决了NDN中传播两种类型的LSA,邻接LSA和前缀LSA。
2. 链路状态通告
邻接LSA:将路由器周围所有活跃的链路状态进行广播,状态项包括邻接路由器名称和之间链路的权重系数。当路由链路变化时,就会被网络中周期性发送的”Info”Interest信息探测到,其命名格式为:
/<LSA-prefix>/<site>/<router>/LsType.1/<version>
其中router是路由器的名称,version是特定的LSA随时间变化的不同版本的序号。
前缀LSA:广播一个被路由器注册了的命名前缀,命名格式为:
/<LSA-prefix>/<site>/<router>/LsType.2/LsId.<ID>/<version>
每个前缀LSA只能广播一个命名前缀,路由器可能有多个前缀LSA,每个前缀LSA通过LSA ID区分。为了避免编号的混乱,通过控制前缀的IsValid状态更新前缀LSA。当取消某个命名前缀后,NLSR将IsValid设为0,并广播更新后的前缀LSA,NLSR节点收到这条LSA后从LSDB中删除对应的命名前缀,并且更新FIB表。LSA有声明周期,如果路由器不能定时更新自己的LSA,其他路由器关于该路由器的LSA就会过期。
3. LSDB 同步(LSDB Synchronization):
将LSDB看作一个数据的集合,把LSA的传播问题看作由路由器维护的LSDBs的同步问题。路由器周期性地交换他们LSDB的hash值(类似于文件的身份证)来检测不一致性,如果发现不一致则恢复。这种逐跳的同步方法可以避免不需要的网络泛洪(指将接口收到的数据流向除该接口之外的所有接口发送出去),当网络稳定时,邻居之间只需要相互交换LSDB的hash值即可,而不用互相传递所有的LSAs。此外,这种数据同步方式时接收方驱动的,这意味着路由器只会在具有CPU周期时去拉取LSAs,因此路由器基本不会被频繁的路由器更新整奔溃。
我们当前的实现使用的是 CNNx 同步协议或 Sync [5] 来将LSAs传播到邻居路由器。Sync和CNNx的Repo(存储库)相关联,它允许应用程序在Repo中定义命名数据集合,这个集合被称之为slice,并保持当前路由器与相邻路由器中定义相同的slice的同步。Sync会为Slice中所有的数据计算一个Hash树,并且在相邻路由器之间交换根Hash的值来检测不一致性。如何检测到Hash值不一致,则两个邻居节点会交换Hash树下一层节点的Hash值,直到他们检测到导致不一致性的叶子节点,两个邻居路由器就会交换对应的数据来达成新的一致性。
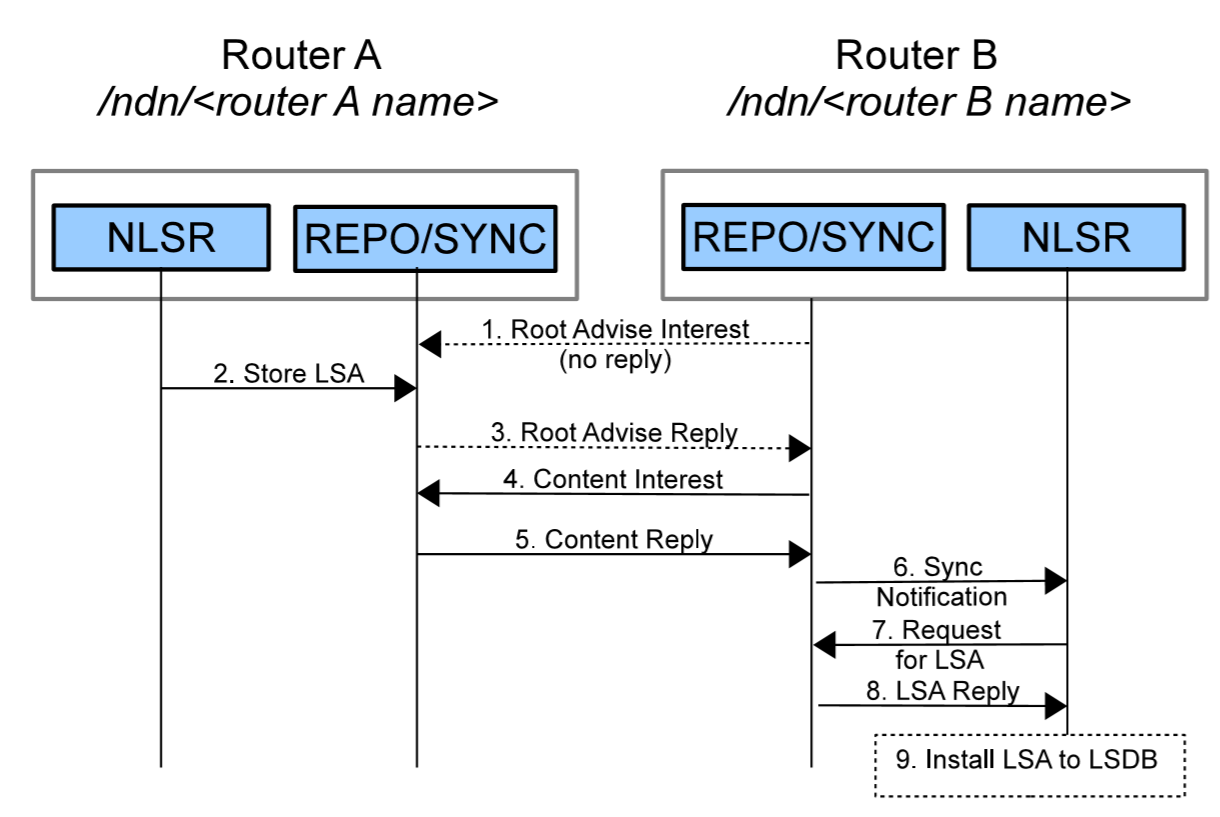
上图1显示了LSA是如何在网络中传播的:
- 为了同步包含LSAs的Slice,Sync协议(路由器B)周期性的对外发送被称为Root Advise的特殊兴趣包,这个兴趣包携带了发送路由器的Slice的hash值(步骤 1);
- 当路由器A创建了一个LSA,并把它写入到Sync的Slice当中(步骤 2),此时路由器A计算的Hash值与路由器B的不同;
- 这将导致路由器A的Sync回复路由器B的 Root Advise(通常,在两个路由器计算得到的hash值相同的情况下,是不需要回复 *Root Advise* 的,当路由器有有新的LSA产生或者移除时会导致路由器的Hash值不一致,此时才需要回复 *Root Advise*),这个回复中携带了路由器A本地计算得到的新的Hash值;(步骤3)
- 收到回复后,路由器B的 Sync 会比对收到的Hash值,并递归的获取到Hash树下一层级的Hash值,直到定位到导致不一致性的叶子节点,最终,路由器B的 Sync 会识别出需要同步的数据(这里所说的数据即为 NLSR 语境下的 LSA),并发送对应的兴趣包将需要同步的数据从路由器A中拉取过来(步骤 4 和 5);
- 接着,路由器B的 Sync 会将新收到的数据名字发给本地的NLSR进行(步骤 6)
- 然后路由器B的NLSR进程就会发送对应名字的兴趣包给本地的 repo 来拉取同步过来的LSA数据(步骤 7 和 8),最后更新到本地的LSDB当中(步骤 9)。
每个 Root Advise 兴趣包都有一个存活期(lifetime),路由器在 Root Advise 兴趣包到期后会发送一个新的 Root Advise 兴趣包。这种周期性传输机制的设计是为了防止 Root Advise 兴趣包丢包的发生(试设想,如果Root Advise 兴趣包的存活期无限大,会一直等待回复,如果 Root Advise 兴趣包在传输的过程中丢失了,而发送方又不知道,且不重传,那么发送方会以为没有新的更新,一直不去拉取最新的更新),从而降低由于丢包带来的路由收敛延迟。但是,如果数据包的丢失率很低,频繁的发送 Root Advise 兴趣包亦会带来无意义的额外开销。在理想情况下,我们希望根据路由需求和网络特性来调整 Root Advise 兴趣包的发送频率。为了支持这个特性并解决 CNNx Sync 实现中的一些其它问题,我们正在致力于开发内建有同步机制的新版本的NLSR,以实现相同的LSA逐跳传播的效果。
4. 多路径计算(Multipath Calculation)
基于 邻接LSAs(Adjacency LSAs)提供的网络节点间的连接信息,每个NLSR节点都能构建出完整的网络拓扑。接着路由器只需运行一个简单的扩展 Dijkstra (有权图最短路径问题)算法便可以为每一个目的节点计算出多跳路由。从 前缀LSAs(Prefix LSAs)中,我们可以知道每个路由器都关联了哪些前缀。我们可以综合上述的信息计算出到达每个名称前缀的下一跳列表。
我们设计的NLSR中某个路由器计算多路径路由的方式如下:
- 首先路由器移除(并非断开,只是排除)到除了一个邻居外的其它直接相连的邻居的路径(即,只保留一个直接相连的邻居);
- 然后使用 Dijstra 算法计算计算当前路由器到网络拓扑中其它所有节点的开销,并记录;
- 接着对每一个邻居都重复上述过程;
- 最后路由器到网络上任意的其它节点都会有多条路径,并且每条路径都有一个开销,然后根据开销进行排名,就能得到到每个目的地的排好序的下一跳列表。
需要提一嘴的是,NLSR支持让用户自行配置对某个名称前缀最多能有几条路径插入到FIB当中,这样当路由器的邻居很多的情况下FIB表的大小也是可控的。但是计算开销仍然会随着 Face 接口数量的增加而增加,因为我们需要遍历所有的 Face 接口来找到所有可能的路径。我们计划探索其它多路径计算算法来解决这个问题。
与IP不同的是,NDN中的路由信息仅作为转发平面的提示信息(参考信息),转发平面可以根据PIT表中维持的状态来观察数据交付的性能,然后结合实际观测值和来自路由协议排名信息来对每个名称前缀的多条路径进行排序。即便如此,路由协议中的排名信息对于初始时将一个兴趣包转发到指定前缀以及在当前路由无法检索数据时用于探索别的可用路由都是非常重要的。
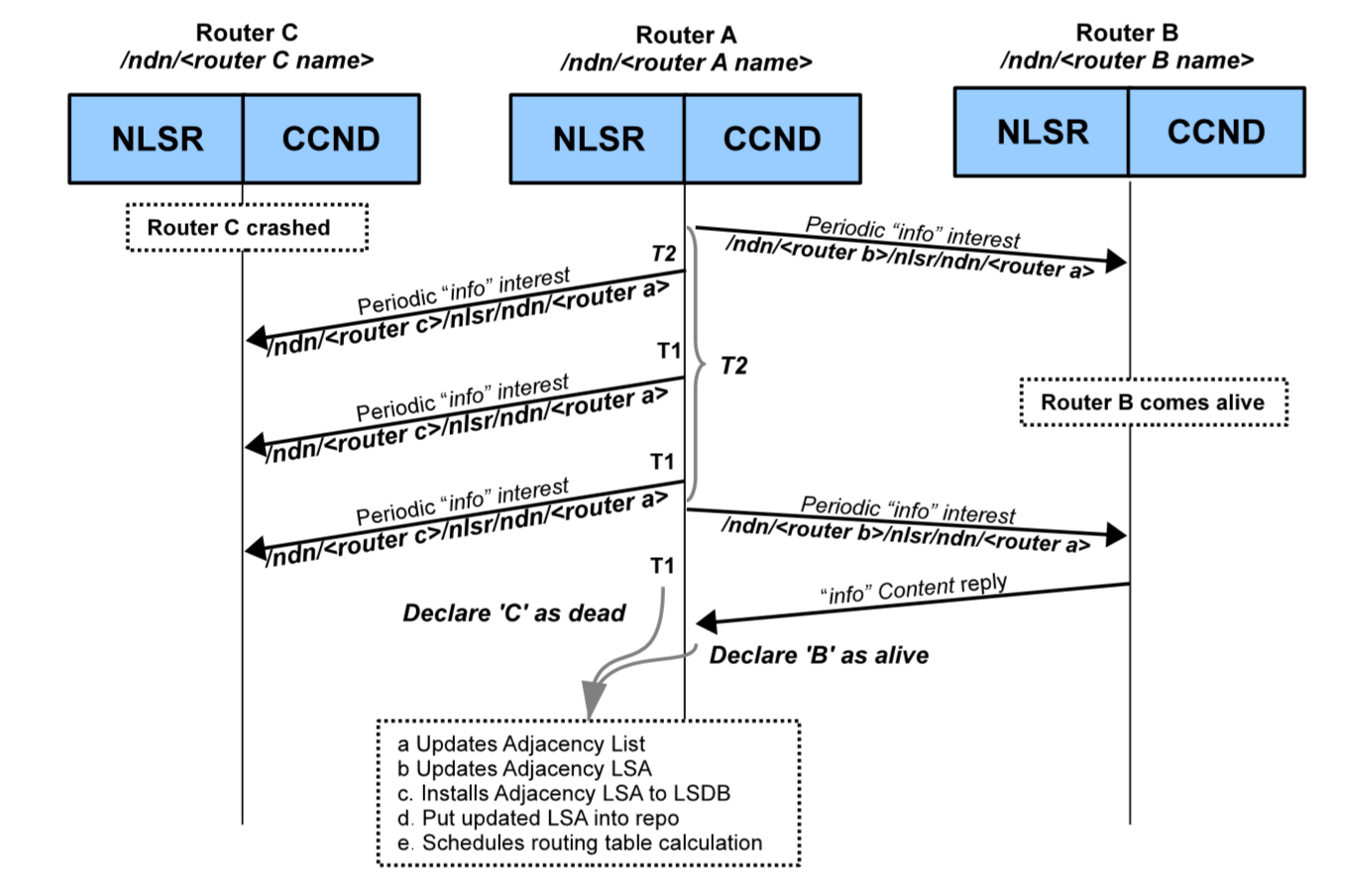
5. 故障与恢复检测(Failure and Recovery Detection)
NLSR通过周期性的向每个邻居节点发送 info 兴趣包来检测链路故障和远端的NLSR进程故障,如果 info 兴趣包超时了,则NLSR会在较短的间隔内多次发送 info 兴趣包,这样可以防止 info 兴趣包丢包带来的影响。如果在此期间(这个时间包含info兴趣包超时后的若干次重传时间)邻居节点没有响应,则NLSR会将这个邻居节点的状态判别为 down ,与该邻居节点相连的链路也标记为链路故障。检测到故障之后,NLSR仍然会向故障邻居发送 info 兴趣包来检测故障是否恢复,但此时发送 info 兴趣包的时间间隔应该相对长一点,避免由于长期故障导致较大的无用开销。需要注意的是,检测到故障时NLSR时无法区分是链路的故障还是远端NLSR进程的故障,但是无论是哪种故障发生,故障链路都不会用于传输数据,所以在目前的设计里不区分这两种故障也无伤大雅。
当邻居节点从故障中恢复时,NLSR会收到对 info 兴趣包的恢复,接着NLSR便会将该邻居的状态标记为 Active 。这个操作会导致 邻接LSA 的更新(产生新版本的邻接 LSA),并将新的邻接LSA传播到网络中,并准备启动路由表计算任务。下图2展示了节点A是如何检测到节点C的故障,以及时如何检测到节点B从故障中恢复的。
6 安全(Security)
每个NDN的数据包(Data Packet)都是经过数字签名的,并且生成的数字签名是组成数据包的一部分。签名包含名字、内容和少量对签名验证有用的支持数据 ,支持数据中很重要的一部分是key locator,它指示了用于给这个数据包签名的 key 的名称,这样接收者就能通过这个名称去拉取到给这个数据包签名的 key(当然我们只能拉取到公钥或证书,不能拉取到私钥),进而验证这个数据包的签名。
一个具有有效签名的LSA(即,这个 LSA的签名是验证通过的)仅仅说明了这个LSA的签名是由其 key locator 域指向的 key 的私钥签名的,它并没有告诉我们拥有这个 key 的路由器是否能合法的生成LSA。举个例子来说,攻击者可以使用其私钥签名一个 前缀LSA(Prefix LSA),并将该LSA注入到路由系统中(此时该 LSA的签名验证是可以通过的,但是实际上这个LSA不是一个合法的 LSA)。为了检测签名信息的有效性,我们需要验证此LSA是否是由授权的NLSR进程签名的,换句话说,我们需要验证 key 的名字中包含的相关的NLSR进程是授权的。即便如此,攻击者还是可以使用与某个有效 key 相同的名字的包,塞入攻击者自己的key。所以,我们需要一个信任模型来验证 key 的有效性。
NLSR是一个域内路由协议(intra-domain routing protocol),在单个网络域中,通常会有一个网络管理员(信任锚)可以验证网络中 keys 的真实性。因此我们将这个信任锚用于给网络中的 key 进行签名和验证,这样做易于构建和管理。我们可以简单的让信任锚对所有路由器的公钥进行签名,但实际上用一个 key 来对大量的 key 签名是存在很大的安全风险的。为了解决这个问题,我们在信任锚上设计了一个划分5个等级的层级结构,它将信任锚中 key 的签名职责限制到一个较小的范围。表2展示了每个等级 key 的命名,需要注意的是,所有 key 名称的最后一个组件(component)都是这个 key 的hash值(在表中未展示出来),所以当某个路由器发送兴趣包拉取一个 key 时, 总能保证拉取到的 key 是和名称所匹配的。
表 2 Keys Names
| Key Owner | Key Name |
|---|---|
| Root | /<network>/keys |
| Site | /<network>/keys/<site> |
| Operator | /<network>/keys/<site>/%C1.O.N.Start/<operator> |
| Router | /<network>/keys/<site>/%C1.O.R.Start/<router> |
| NLSR | /<network>/keys/<site>/%C1.O.R.Start/<router>/NLSR |
首先在顶层的是 Root key,为当前网络的管理员所拥有,第二层包含一系列的 site keys,由网络中某个网站的管理员所拥有,并且使用 Root key 进行签名的。每个 site key 可以签名一系列的 operator keys(通常一个网站由多个操作员),每个 operator key 又能签名一系列的 router keys,每个 router key 又能给运行在同一个路由器上的NLSR进程签名NLSR使用的 key,最后,路由器使用 NLSR key 给每个由NLSR生成的数据签名。需要注意的是,我们目前的设计里使用 CNNx sync/repo 来传播 keys,所以所有的 keys 都共享一个同一个前缀 /<network>/keys (前文中有提到过这是 CNNx 机制限制的,所有用于同步的数据都需要共享同一个相同的前缀),但是我们现在设计的 keys 命名方案确实是一个层级的结构。此外,我们使用两个标记 %C1.O.N.Start 和 %C1.O.R.Start 来分别指示 operator keys 和 router keys。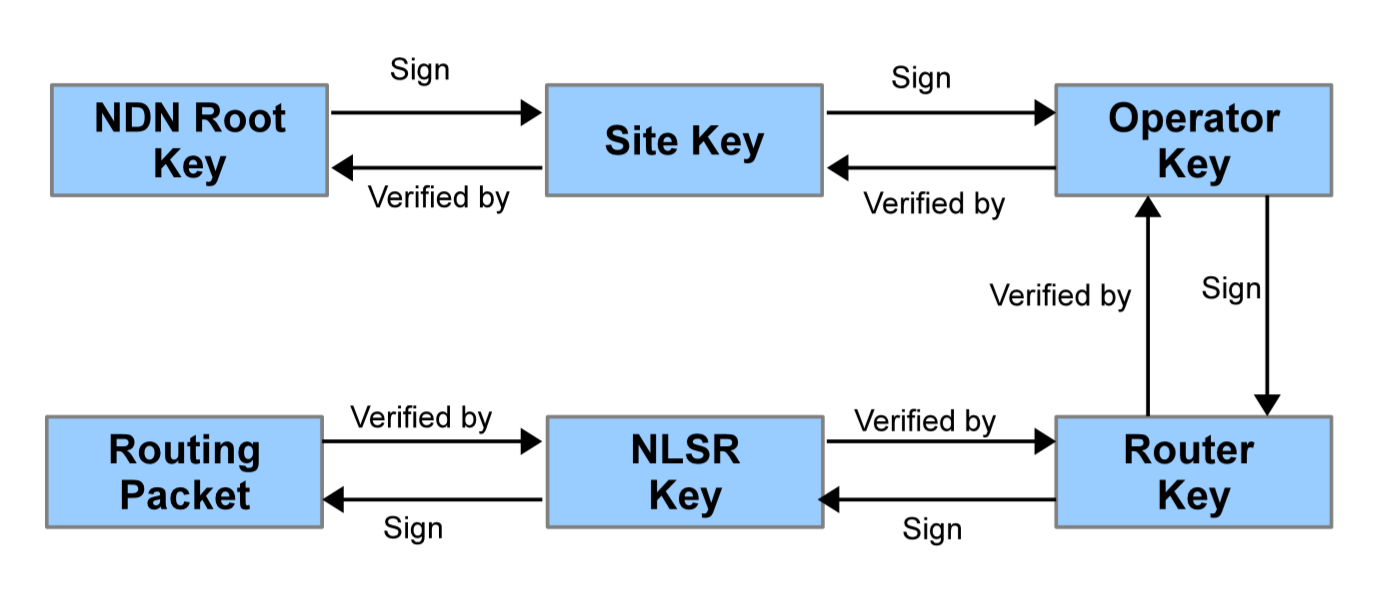
图 3 每个NLSR包的签名和认证链
NLSR严格执行基于信任锚的信任模型,图3描绘了每个NLSR包的签名和认证的流程。当NLSR路由器发送一个LSA到网络中时,它会使用它的 NLSR key 对数据包进行签名,并把用来签名的 NLSR key 的名字放在数据包(Data Packet)的 SignedInfo/KeyLocator/KeyName 域里面。每当收到一个LSA,NLSR路由器会从本地的内容缓存(content store)或者 repo (key 可能已经通过 key repo 进行分发 )中获取包中指定的 key,并验证内容的签名,同时NLSR会检查这 key 是否确实属于生成LSA的那个NLSR进程。接着重复上述过程,直到NLSR拉取到信任锚的自签 key。如果在这个过程中任意一步的 key 拉取失败,或者NLSR发现拉取到的 key 是由一个未授权的 key 签名的,亦或是最后的验证步骤没有到达信任锚,都认为该LSA是非法的。需要注意的是,一旦一个 key 被验证有效了,我们将记录这个信息,以后再收到由该 key 签名的数据包时,不需要再对这个 key 进行重复验证。
5.4 NDN转发策略:
路由器转发并在PIT中维护未响应请求的状态表。同时设置了Interest请求否定应答NACK,根据否定原因进行网络故障诊断。
- 新来的Interest请求:如果CS没有,就创建PIT,将Interest转发给优先级最高的可用接口。没有可用接口,就返回阻塞应答,同时开启一个计时器,以便超时重传。
- 后续Interest请求:如果请求之前PIT中有,但是兴趣包的nonce还不一样,如果计时器每超时,就不转发后续请求了。
- 请求的否定应答:收到否定应答后,会向优先级次之的接口请求数据。
- 接口状态的探测:探测到原来不可用的接口可用了并且可能更好的获取兴趣包就可以路由。
其他转发策略:
- 基于概率的自适应转发策略。通过蚁群算法计算转发接口的选择概率
- 基于熵值的概率转发策略:通过熵值的概念分配各种属性的权重,从而设计接口的转发策略。
- 集中式架构的转发策略:比如将转发路径通过过滤器加到分组的首部。(感觉这就和IP没什么区别了?)