
EasyRL-3
深度Q网络——DQN
传统的强化学习算法会使用表格的形式存储状态价值函数V (s) 或动作价值函数Q(s, a),但是这样的方法存在很大的局限性。例如,现实中的强化学习任务所面临的状态空间往往是连续的,存在无穷多个状态,在这种情况下,就不能再使用表格对价值函数进行存储。价值函数近似利用函数直接拟合状态价值函数或动作价值函数,降低了对存储空间的要求,有效地解决了这个问题。
为了在连续的状态和动作空间中计算值函数Qπ(s, a),我们可以用一个函数Qϕ(s, a) 来表示近似计算,称为价值函数近似(value function approximation)
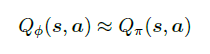
深度Q 网络是基于价值的算法,在基于价值的算法里面,我们学习的不是策略,而是评论员(critic)。评论员的任务是评价现在的动作有多好或有多不好。
评论员无法凭空评价一个状态的好坏,它所评价的是在给定某一个状态的时候,如果
接下来交互的演员的策略是π,我们会得到多少奖励,这个奖励就是我们评价得出的值。因为就算是同样的状态,接下来的π 不一样,得到的奖励也是不一样的。
动作价值函数
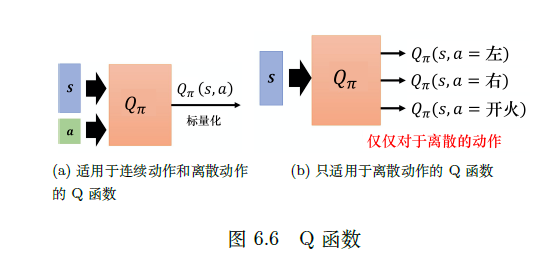
还有另外一种评论员称为Q 函数,它又被称为动作价值函数。状态价值函数的输入是一个状态,它根据状态计算出这个状态以后的期望的累积奖励(expected accumulated reward)是多少。动作价值函数的输入是一个状态-动作对,其指在某一个状态采取某一个动作,假设我们都使用策略π ,得到的累积奖励的期望值有多大。
Q 函数有一个需要注意的问题是,策略π 在看到状态s 的时候,它采取的动作不一定是a。Q 函数假设在状态s 强制采取动作a,而不管我们现在考虑的策略π 会不会采取动作a,这并不重要。在状态s强制采取动作a。接下来都用策略π 继续玩下去,就只有在状态s,我们才强制一定要采取动作a,接下来就进入自动模式,让策略π 继续玩下去,得到的期望奖励才是Qπ(s, a) 。
我们可以估计某一个策略的Q 函数,接下来就可以找到另外一个策略π′ 比原来的策略π 还要更好。
双深度Q 网络
DDQN 的方法可以让预估值与真实值比较接近。
在原来的深度Q 网络里面,我们穷举所有的a,把每一个a 都代入Q 函数,看哪一个a 可以得到的Q 值最高,就把那个Q 值加上rt。
但是在DDQN 里面有两个Q 网络,第一个Q 网络Q 决定哪一个动作的Q 值最大(我们把所有的a 代入Q 函数中,看看哪一个a 的Q 值最大)。我们决定动作以后,Q 值是用Q′ 算出来的。
假设我们有两个Q 函数——Q 和Q′,如果Q 高估了它选出来的动作a,只要Q′
没有高估动作a 的值,算出来的就还是正常的值。假设Q′ 高估了某一个动作的值,也是没问题的,因为只要Q 不选这个动作就可以。