
Map-Reduce实现词频统计
主机保持几个数据结构。对于每个 map 任务和 reduce 任务,它存储状态(空闲、正在进行或已完成)和辅助计算机的标识(对于非空闲任务)。主服务器是从映射任务传播中间文件区域位置以减少任务的管道。因此,对于每个完成的 map 任务,master 存储 map 任务生成的 R 中间文件区域的位置和大小。当地图任务完成时,将收到此位置和大小的更新信息。信息被递增地推送给正在进行减少任务的工人。
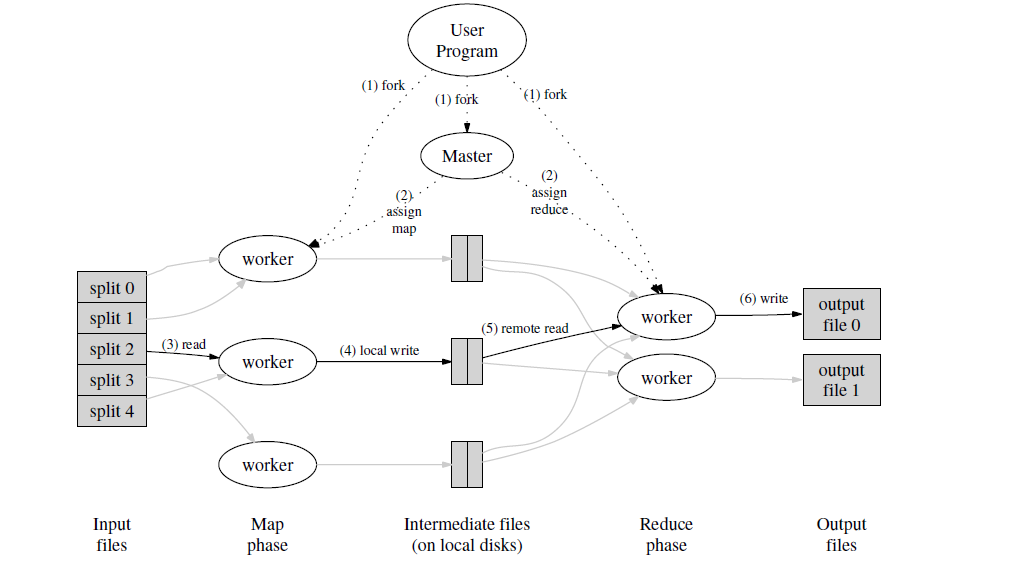
可以看出大致MapReduce的流程:启动一个Master(Coordinator协调者)分配多个任务给worker做Map任务。
然后Worker完成Map任务后返回中间值一组KV,接着协调者再将这些KV分发给后继的Worker根据KV进行Reduce任务,最后对Reduce进行一个总的处理进行返回。
对于词频统计的例子:
map阶段:首先读入文件名作为key,对文件的内容分成单词,每个单词的值对应key,1为value,也就是单词出现了一次。
reduce阶段:对key相同的键值对的value进行累加,也就是统计相同的单词的个数。

核心的Map和Reduce原理
1 | func Map(filename string, contents string) []mr.KeyValue { |
通过go语言的协程机制及进程间通信模拟coodinator和worker之间的交互。worker不断向coodinator发送进程间通信请求,coodinator依次为每个worker(不同的go routine)派发map任务和reduce任务。
1 | // start a thread that listens for RPCs from worker.go |
3.2 Coordinator保持几个数据结构。对于每个 map 任务和 reduce 任务,它存储状态(空闲、正在进行或已完成)(对应JobCondition)和辅助计算机的标识(对于非空闲任务)(对应JobType)。master负责map和reduce任务的统筹管理。因此,对于每个完成的 map 任务,master 存储 map 任务生成的 中间文件区域的位置和大小(mr-tmp*)。当map任务完成时,将收到此位置和大小的更新信息。信息推送给正在进行reduce任务的worker。
定义了一些用于Job类型,状态和coordinator状态的常量
1 | // condition of job |
worker通过调用Coordinator.DistributeJob获取任务,返回一个Job任务
1 | func RequireTask(workerId string) *Job { |
Distribute分派任务:
1 | func (c *Coordinator) DistributeJob(args *ExampleArgs, reply *Job) error { |
分配map和reduce任务
1 | func (c *Coordinator) makeMapJobs(files []string) { |
worker按照reply的类型分别执行map(输出到mr-tmp中)和reduce(输出到mr-out中)。
1 | func DoMap(mapf func(string, string) []KeyValue, response *Job) { |
3.3容错处理
worker异常
==master节点会周期性的ping所有的worker节点。如果在一定的时间内没有收到worker的回复,则认为该worker已经出现异常==。当worker出现异常时,采取如下措施:
该worker已完成的所有Map Task无效,需要重新执行, 已完成的所有Reduce Task,不需重新执行。
该worker正在运行的Map Task或Reduce Task无效,需要重新执行。
对于已完成的任务,只需要重新执行Map Task的原因是,Map阶段的输出是作为中间变量存储在local disk上的,因此当worker出现异常时,无法获取中间数据,需要重新执行。对于Reduce Task来说,其输出是直接写入分布式文件系统中的,因此无需重新执行。
当Map Task在worker A上执行完毕后,此时worker A发生故障,根据容错处理,调用worker B重新执行Map Task。此时,master结点将会通知所有的reduce worker发生异常,并让还没有从worker A上读取结果的reduce worker从worker B上读取数据。
master异常
我们可以在master节点上周期性地进行check,并记录checkpoint,这样当master出现故障时,我们就可以根据checkpoint来进行恢复。
3.4 ~ 3.6 如何加速并行处理的过程?
利用局部性 Locality
在分布式系统中,网络带宽通常是稀缺资源,很容易成为系统瓶颈。在MapReduce的任务中 至少需要M*R次的网络传输,才能将中间文件发送给reduce所在的worker节点上。同时把输入文件发送给map任务所在的worker 也是非常消耗网络带宽的事情。为了解决这个问题:
- master节点会将Map Task尽量分配给离所需数据最近的worker结点。
- 可以通过仅将map任务分配给本来就有所有输入文件的节点上,来减少一次网络调用使得性能得到提升。
- 同时还可以使用一些流处理的思路优化shuffle的过程,那就是 当一个map任务完成后通知main进程后,main进程立即通知reduce任务拉取其中一份文件,而不必等到所有map任务全部执行完毕后进行网络传输而提高了并行性。
合理的任务粒度 Task Granularity
应该配置多少个任务执行map,多少个任务执行reduce?任务拆分过多加剧网络传输的负担。 而任务拆分的过少又会导致并行度不够而降低整体的执行效率。
为此 一些经验性的配置是 map任务通常为输入文件总大小除以64M的值(这源于底层的分布式文件系统是以64m为一个chuck进行存储的),reduce的数量通常是map任务的一半。同时 为了发挥机器本身的多核特性,一台机器上可以指定多个map reduce任务来执行 通常是任务总数的百分之一。
备用任务 Backup Tasks
如果最后的几个任务执行时间过长怎么办?存在这种情况,10个任务用5分钟完成了其中9个,但最后一个任务因为当前机器的负载过高花费了20分钟执行完毕,这么整个任务的执行周期就是20分钟。 如何能应对这一问题呢?
当仅剩下1%的任务时,可以启动备用任务,即同时在两个节点上执行相同的任务。这样只要其中一个先返回即可结束整个任务,同时释放未完成的任务所占用的资源。