
服务于边缘:基于ICN的边缘计算服务架构
服务于边缘:基于ICN的边缘计算服务架构
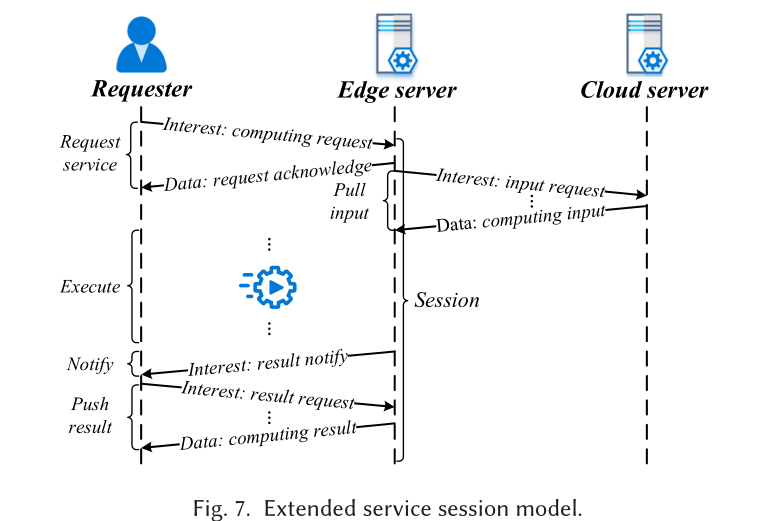
基于ICN的边缘计算服务架构,包含==边缘计算服务会话模型、服务请求转发策略和服务动态部署机制==。
1. 介绍
与CDN(内容交付网络)相比,边缘计算具有更多的分散节点。此外,实时计算带来的服务器负载的动态变化更为显著。
边缘计算还可以缓存计算服务,我们的边缘服务器不仅可以执行计算任务,还可以作为ICN路由器运行以转发数据包。
2.基于邻接分段的模式:邻接SID类似于传统IP网络中的出接口。
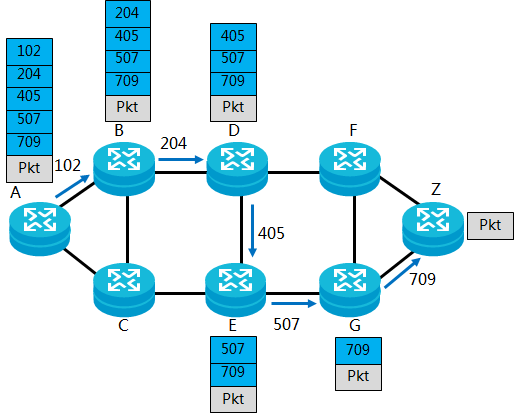
Adjacency Segment ID:邻接段ID
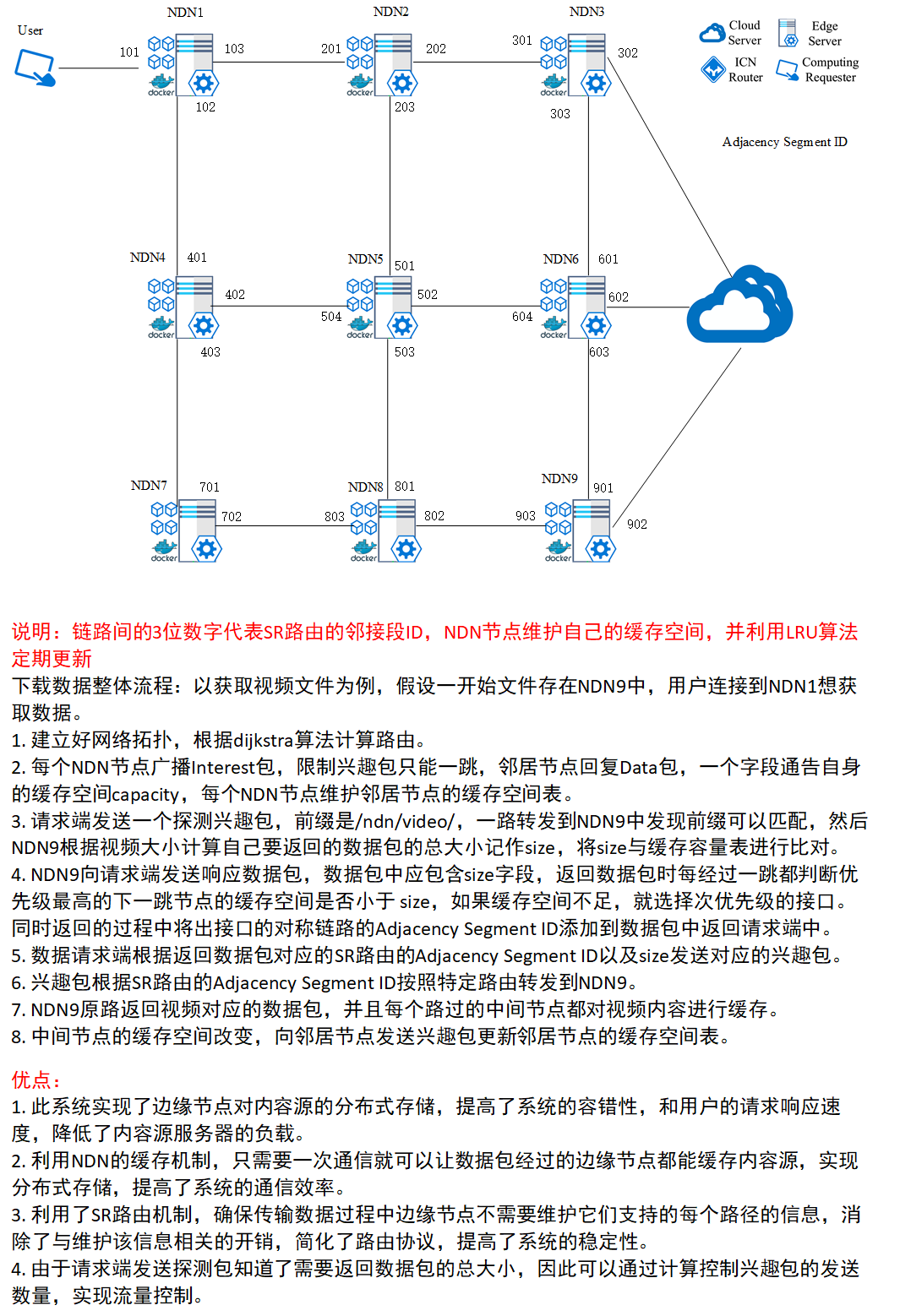
说明:链路间的3位数字代表邻接段ID,NDN节点都作为边缘服务器,维护自己的缓存空间,并利用LRU算法定期更新
整体流程:以获取视频文件为例,假设一开始文件存在边缘节点NDN9中
说明:链路间的3位数字代表SR路由的邻接段ID,NDN节点维护自己的缓存空间,并利用LRU算法定期更新
用户下载数据整体流程:以获取视频文件为例,假设一开始文件存在NDN9中,用户连接到NDN1想获取数据。
- 建立好网络拓扑,根据dijkstra算法计算路由。
- 每个NDN节点广播Interest包,Interest包中有一个字段通告自身的缓存空间capacity,每个NDN节点维护全局的缓存空间表。
- 请求端发送一个探测兴趣包,前缀是/ndn/video/,一路转发到NDN9中发现前缀可以匹配,然后NDN9根据视频大小计算自己要返回的数据包的总大小记作size,将size与NDN1的缓存容量表进行比对。
- NDN9向请求端发送响应数据包,数据包中应包含size字段,返回数据包时每经过一跳都判断优先级最高的下一跳节点的缓存空间是否小于 size,如果缓存空间不足,就选择次优先级的接口。同时返回的过程中将出接口的Adjacency Segment ID添加到数据包中返回请求端中。
- 数据请求端根据返回数据包对应的SR路由的Adjacency Segment ID以及size发送对应的兴趣包。
- 兴趣包根据SR路由的Adjacency Segment ID按照特定路由转发到NDN9。
- NDN9原路返回视频对应的数据包,并且每个路过的中间节点都对视频内容进行缓存。
- 中间节点的缓存空间改变,向邻居节点发送兴趣包更新自身容量。
背景:原来只有一个服务器存有数据,现在想实现分布式存储。
用户上传数据整体流程:
- 建立好网络拓扑,根据dijkstra算法计算路由。
- 每个NDN节点广播Interest包,Interest包中有一个字段通告自身的缓存空间capacity,每个NDN节点维护全局的缓存空间表。
- 用户发送包含上载数据大小的兴趣包到NDN1,NDN1首先判断自身的缓存空间是否满足,如果满足就缓存数据 (即j = 1),不满足则根据存力表找到可以缓存数据的最短路径节点NDNj。
- NDNj根据存力表判断哪些节点不可以作为缓存节点,将路由表中含有不满足条件的缓存节点的路由条目删除。
- 在所有满足2跳及以上的路径中选择一跳最短路径,并根据源路由技术转发兴趣包通知路由最远节点(NDN6),兴趣包中应该包含一个字段为要上传的视频的size,NDN6返回一个数据包作为确认。
- NDN6根据size大小向NDN1发送对应数量的请求兴趣包,NDN1返回对应的内容数据包,中间节点2,3,6都会对数据进行缓存。
优点:
- 此系统实现了边缘节点对内容源的分布式存储,提高了系统的容错性。
- 利用NDN的缓存机制,只需要一次通信就可以让数据包经过的边缘节点都能缓存内容源,实现分布式存储,提高了系统的通信效率。
- 利用了SR路由机制,确保传输数据过程中边缘节点不需要维护它们支持的每个路径的信息,消除了与维护该信息相关的开销,简化了路由协议,提高了系统的稳定性。
- 由于请求端发送探测包知道了需要返回数据包的总大小,因此可以通过计算控制兴趣包的发送数量,实现流量控制。
边缘服务器资源共享整体流程:
1)设置网络中心服务器并通告全网边缘服务器;
2)各边缘服务器建立本地链路状态数据库及自身存储能力并告知云服务器;
3)云服务器建立全网拓扑结构图及各个边缘服务器的存储能力的存力表并分发给所有边缘服务器;
4)边缘服务器计算向其他各边缘服务器转发的转发代价;
5)需要共享数据的边缘服务器A根据存力表和转发代价确定一个边缘服务器B作为转发终点。
6)边缘服务器A利用邻接SID信息根据SR路由向边缘服务器B发送存储通告兴趣包。
7)边缘服务器B返回存储通告数据包作为应答确认。
8)边缘服务器B发送存储请求兴趣包向边缘服务器A请求数据。
9)边缘服务器A返回存储应答数据包到边缘服务器B,途径的边缘服务器缓存存储应答数据包。
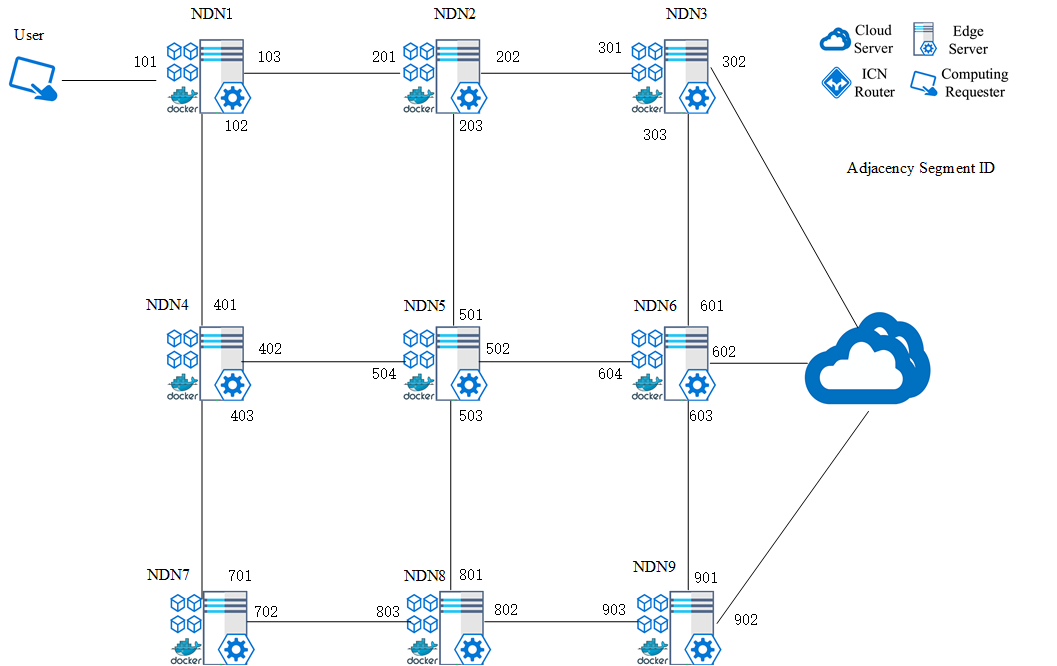
1.1 边缘路由器建立好全局拓扑,全网拓扑结构图数据信息表
| 节点名称 | 相邻节点名称 | 链路的路由代价 |
|---|---|---|
| NDN1 | NDN2 | 110 |
| NDN1 | NDN4 | 100 |
| NDN2 | NDN3 | 100 |
| NDN2 | NDN5 | 120 |
| NDN3 | NDN6 | 100 |
| NDN4 | NDN5 | 130 |
| NDN4 | NDN7 | 100 |
| NDN5 | NDN6 | 120 |
| NDN5 | NDN8 | 100 |
| NDN6 | NDN9 | 110 |
| NDN7 | NDN8 | 100 |
| NDN8 | NDN9 | 130 |
1.2 进而可以根据Dijkstra算法求得每个节点到网络中其他节点的路径及最短距离,以NDN1为例:
| 目的节点 | 路径 | 路由代价 |
|---|---|---|
| NDN2 | 1->2 | 110 |
| NDN3 | 1->2->3 | 210 |
| NDN4 | 1->4 | 100 |
| NDN5 | 1->2->5 /1->4->5 | 230 |
| NDN6 | 1->2->3->6 | 310 |
| NDN7 | 1->4->7 | 200 |
| NDN8 | 1->4->7->8 | 300 |
| NDN9 | 1->2->3->6->9 | 420 |
2. 每个NDN节点广播Interest包,Interest包中有一个字段通告自身的缓存空间capacity,每个NDN节点维护全局的缓存空间表。
| 节点名称 | 缓存容量 |
|---|---|
| NDN1 | 5T |
| NDN2 | 7T |
| NDN3 | 3T |
| NDN4 | 1T |
| NDN5 | 6T |
| NDN6 | 4T |
| NDN7 | 9T |
| NDN8 | 2T |
| NDN9 | 8T |
3. 用户发送包含上载数据大小的兴趣包到NDN1,如果NDN1的缓存空间够,返回一个data,如果NDN1存储空间不够,就需要根据存力表找到一个存储空间够的开销最小的节点发送兴趣包,比如说存一个6T的数据,就需要将兴趣包转发到NDN2中,由NDN2返回data。
4.NDN1根据要上载的数据大小发送对应数量的兴趣包,用户发送数据包数据,NDN1将数据存在自身的缓存中。
5. NDN1根据存力表判断哪些节点不可以作为缓存节点,将路由表中含有不满足条件的缓存节点的路由条目删除。(假如需要上载一个2.5T的数据,NDN4和NDN8被排除在外,剩下的里面选3跳及以上的条目中代价最小的,最后选定是1->2->3->6。)(1.2中加粗的部分)
6. NDN1向NDN6根据SR路由的邻接SID转发兴趣包,(兴趣包包括数据大小size和邻接SID 103,202,303),兴趣包沿着确定的路径走到NDN6,NDN6反馈回一个数据包用作应答确认。
7.然后NDN6根据size大小向NDN1发送对应数量的请求兴趣包,NDN1返回对应的内容数据包,中间节点2,3,6都会对数据进行缓存。
| 目的节点 | 所有路径 | 路由代价Cr | 缓存代价Cs | 通信代价Cc | 邻接段标识 |
|---|---|---|---|---|---|
| node6 | 5→6 | 120 | 100 | 220 | 601 |
| node8 | 5→8 | 100 | 80 | 180 | 803 |
| node9 | 5→6→9 | 230 | 180 | 410 | 601,903 |
| node9 | 5→8→9 | 230 | 160 | 390 | 803,902 |